この文書はProject JXTA上で公開されているJXTA Search White Paperの日本語訳です。
この文書の訳者は吉澤(http://muziyoshiz.jp/)です。誤訳の指摘や改善案は、常に歓迎します。
初出: 2001/11/15
最終更新日: 2004/12/29
JXTA Searchは、InfrasearchのGene KanとYaroslav Faybishenkoがピアツーピアプロトコルを使って複数のウェブサーバを接続するデモサーチエンジンを作った2000年6月に生を受けた。このデモは分散したサーバ集合へのウェブフロントエンドから成り、それぞれのノードの動作は特定の型の問い合わせ(query)に応答するためにハードコードされていた。Infrasearchの創設者は問い合わせを、回答できる可能性が最も高いネットワークピア達へと配る、というアイデアを思いついた。例えば、Infrasearchサーチエンジンは以下のような問い合わせに対して賢く応答した。
それから約一年後の現在、InfrasearchチームはSunのProject JXTA(http://jxta.org)の一部となっているが、今も同じ任務と目的を持っている。その目的とはウェブサーバから小さいコンピュータといったあらゆる機器に対して共通の分散問い合わせメカニズムを提供し、JXTAとInfrasearchの分散検索技術によってウェブを効率的にP2P化することである。加えて元のInfrasearchデモは、ウェブ上だけでなくJXTAフレームワークの一部としても動作するように拡張されてきた。現在InfrasearchはJXTA Searchという形で、JXTAフレームワークのためのデフォルトの検索方法を提供している。
JXTA Search上の通信はQuery Routing Protocol(QRP)と呼ばれるXMLプロトコルを通して実行される。QRPはJXTA Searchネットワーク上で問い合わせを送受信するためのメカニズムと、ネットワーク内のノードに対するメタデータを定義するためのメカニズムを定義する。JXTA Searchネットワークは以下の関係者(participants)から成っている。
コンシューマアプリケーションは一番近いJXTA Searchハブを通してJXTA Searchネットワークへと要求を送信する。ハブはプロバイダのメタデータに基づいて、知られたプロバイダのうちのどれが問い合わせを受け取るべきかを決定する。ハブはプロバイダに要求を送信し、応答を受信して、その応答をコンシューマへ送り返す。
多くのアプリケーションでは、プログラムはピアツーピアの流儀でプロバイダとコンシューマの両方を演じるように機能する。物理的には、プロバイダは単一のコンピュータかまたは負荷分散された(load-balanced)マシンの集合である。典型的に、コンシューマはそれがウェブサービスだとしても単一のコンピュータである。ネットワークはマシンの群れ(cloud)である。プロバイダとコンシューマは、ネットワーク全体へのヴァーチャルなアクセスを提供する特定のハブマシンを通してネットワークに接触する。(典型的にプロバイダとコンシューマは異なるハブマシンに接触する。)
最初にちょっと見た感じでは、JXTA Searchは分散ネットワークのための単なるメタサーチエンジンに見える。しかし、HTTP scrapingのようなメタサーチの慣例的なテクニックとは対照的に、JXTA Searchは問い合わせと応答の交換のために共通のプロトコルを定義している。このQuery Routing Protocolは、ネットワーク内の関係者がそのプレゼンテーション層の構造を理解する必要なく、シームレスな方法で情報を交換できるようにする。
分散されたサービスとアプリケーションの間で相互動作を行うためのこの技術を用いたアプリケーションは多くの種類のドメインで見られ、これは公開されていてアクセス可能なウェブの検索から取引相手のプライベートネットワークにまで渡る。ピアツーピアフレームワークの中で問い合わせを効率的にルーティングするためのこのネットワークのアプリケーションの例は、SunのJXTA SearchのJXTAバインディングに具体化されている。Gnutellaコミュニティは似たようなアプローチを見つけていて、これはClip2のリフレクタ(http://clip2.com)の形式でネットワークを拡大することが望まれるアプローチである。
深いウェブサーチのもう一方の例はSunのJXTA Searchウェブクライアントでデモされている。公開ウェブドメインでのこのような技術の必要性はIndustry Standardが発行した最近の調査(http://www.thestandard.com/article/0,1902,18134,00.html(訳注:現在このページは存在していない))によって証明されていて、その調査では5500億を越えるコンテンツ文書が分散された情報の中に含まれていると見積もっている。比較して、主要なサーチエンジンであるGoogleは、見積もられた120億の静的なページの中のたった6億ページだけを検索することができる。加えて、アプリケーションサーバやウェブ上で可能な企業システムの増加によって、伝統的な方法では検索できないコンテンツの量が急速に増加している。
JXTA Searchは広い(wide)と深い(deep)という2つの互いに補いあう検索型を意図されている。JXTAによって拡張されたウェブの概念は、PCやハンドヘルドや携帯電話といった分散機器に対する広い検索と、ウェブサーバのような高価なコンテンツ情報源に対する深い検索の両方をサポートする(図1)。
図1: JXTA Searchはネットワークに対する広い検索と深い検索の両方をサポートする。
JXTA Searchのような分散アプローチは、以下の3つの重要な点でcrawler-basedサーチエンジンよりも深い検索に適している。
データがデータベースからHTMLへと移り、そしてまた再びデータベースへ戻るというこのプロセスは元々非効率的で、エラーが起こりやすい。加えてコンテンツプロバイダは、(サーチエンジン側での)記事のフォーマットや、ある問い合わせへの応答として(サーチエンジンが)どの記事を表示するかを決定することについて何の制御も持たない。対照的にJXTA Searchのアプローチは、両者(訳注:コンテンツプロバイダとサーチエンジン)に対してそれ以上の柔軟性とデータ交換に対する制御を与えるような、共通の問い合わせ要求と応答のプロトコルを指定する。
JXTA SearchはJXTAフレームワークに基づくオープンなネットワークフレームワークであり、これはJXTAフレームワークを拡張する分散情報ルーティングを可能にする。JXTA Searchは情報プロバイダが自分の回答したい問い合わせについての記述(description)を発行できるようにする。情報コンシューマはネットワークに問い合わせを提出して、ネットワークはそれぞれの問い合わせを全ての関連するプロバイダへとルーティングする。
JXTA Searchフレームワークは以下のものから成っている。
JXTA Searchネットワークはプロバイダの応答の表現について何も行わないことに注意すること。JXTA Searchはプロバイダからの全ての結果を照合し、問い合わせに関する結果のランク付けを行い、それを要求を起こしたクライアントへ返す。クライアントが結果の最終的な表現を実行する。クライアントはウェブページやクライアント側のユーザインターフェイスとして表現することが考えられる。原則的に、一般的なアプリケーションはネットワークに問い合わせて、適合すると見なされた応答に従って処理を行う。
JXTA Searchプロトコルは以下の設計目標を持っている。
JXTA Searchは任意のメッセージングとトランスポートメカニズムを使った、ネットワークに対する抽象的な問い合わせルーティングサービスとして設計された。JXTA Searchは現在2種類のネットワークにバインドされている。その1つはJXTAフレームワーク(HTTPかTCPを使ったJXTA上でXMLを運ぶ = XML over JXTA)で、もう1つはウェブ(HTTP上でXMLを運ぶ = XML over HTTP)である。この文書はその両方のバインディング(binding)とそれらの違いについて説明する。一般に、例の中に出てくるJXTAピアとHTTPサーバやクライアントは自由に入れかえて考えることができる。実際にはシステム内部の技術のいくつかは異なっているが、その原理は同じままである。この2つのバインディングの間で使われるプロトコルは同一であり、解決メカニズムも同様である。主な相違点はルータとクライアントインターフェイスの間に発生する。
図2はJXTA Searchネットワークアーキテクチャを説明している。このJXTA Search/JXTAフレームワークの図では、それぞれのJXTAピアは自分自身のJXTAコア上でプロバイダ、コンシューマと登録サービスのインスタンスを実行することができる。それぞれのピアはJXTA Searchハブサービスと相互動作し、そのハブサービス自身もJXTAコアの上で動作している。
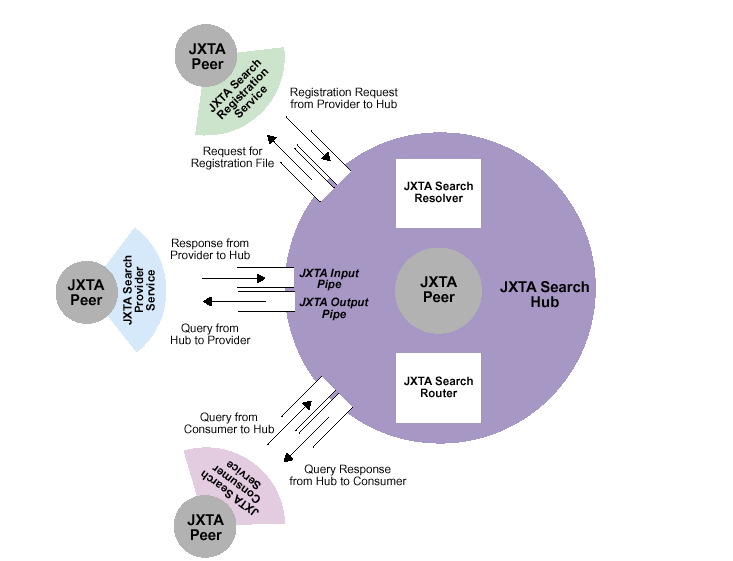
図2: JXTA Searchネットワークアーキテクチャ
JXTA Searchネットワークアーキテクチャは以下のコンポーネントから成っている。
アプリケーションは特定のアクセスポイントを通してネットワークへと問い合わせを送ることで、情報プロバイダを発見する。この問い合わせは本質的に任意の構造を持つXMLメッセージである。問い合わせタグについての制限は何も無い。問い合わせが情報プロバイダへと送られるためには、2つの条件が満たされなければならない。
いったん情報プロバイダがマッチする問い合わせを受け取ると、プロバイダは応答を構成してそれをネットワークへと送り返す。ネットワークは全ての応答を照合して、問い合わせを起こしたアプリケーションへとそれらを返す。ネットワークは実際は競合関係のランキングを評価しないことに注意。この仕事はアプリケーションに任されている。
ネットワークが応答を照合してユーザへ送り返すという事実によってクライアントは非同期の応答をlistenする必要が無くなり、アーカイブを単純にするのを助けている。照合はセキュリティ上の理由からも重要である。例えば、照合は問い合わせを騙すことによる分散DoS攻撃を妨げるのを助けている。しかし、ネットワークメッセージがしばしばピアツーピア接続を確立するために使われることが予想されている。
応答メッセージは任意のXMLで、ネットワークがJXTA Searchプロトコルの中でペイロードとして運ばれるXMLメッセージに対して暗黙のサポートを提供できるようにする。例えば、特定のメソッドタグや識別子をマッチさせるためにJXTA Searchを使うことで、SOAPメッセージをプロバイダからコンシューマへ運ぶことができる。単純でパワフルなenveloping protocol(訳注:いろいろなデータを封筒のように包み込んで運ぶことが出来るプロトコル)とmatching engine(訳注:条件にマッチさせるエンジン)を利用することで、JXTA Searchは位置や資源についての情報を必要とすることなく、プロバイダとコンシューマの探索や相互動作を促進するネットワークアプリケーションを構築することを可能にする。
プロトコルはマシンのアドレスを同定するための問い合わせや応答を必要としない。ある問い合わせ空間はアドレスを明示的に共有することに同意するかもしれないし(例えば、ピアツーピアファイル共有)、一方で他の問い合わせ空間はアドレスを暗黙の内に共有することを選ぶかもしれない(例えば、埋め込まれたXHTMLと共に)。問い合わせと応答の両方の構造は、選択された問い合わせ空間によって、明示的または暗黙的に指定されている。
単一のハブでも潜在的には数十万のプロバイダを扱うのに十分なくらい拡大可能であるけれども、実際には異なるタイプのアプリケーションや専門的なドメインのために、異なるいくつかのハブを動作させるのが望ましい。例えば、ウェブサイトはJavaプログラミングに関係するコンテンツの頂点の集約者としてハブを動作させるかもしれない。そのハブのプロバイダはJavaに焦点を当てたコンテンツを持つ他のサイトかもしれない。しかし、ハブはより一般的な技術系ニュースサイト上で動作するハブへと問い合わせを送ることも有りうる。そのハブのプロバイダはCNetやSlashdotのようなサイトかもしれない。同様に、ピアツーピアネットワーク上では、ハブは似たようなコンテンツや地理や問い合わせ空間を持つピアをグループ化するのに有効な方法になるのではないかと期待されている。
プロトコルはハブ同士を繋ぎ合わせるための方法を定義していない一方で、複数のハブをサポートするためのメカニズムを含んでいる。これらのメカニズムは、応答メッセージの中に包まれた複数の応答に対するサポートと、結果が有効であるための問い合わせ有効期間(query lifetime)の仕様を含んでいる。プロバイダの索引からハブ登録を自動生成するような、複数のハブを維持するためのより洗練されたスキームを開発することが考えられる。しかし、これらのアプローチはこの文書では考察されていない。
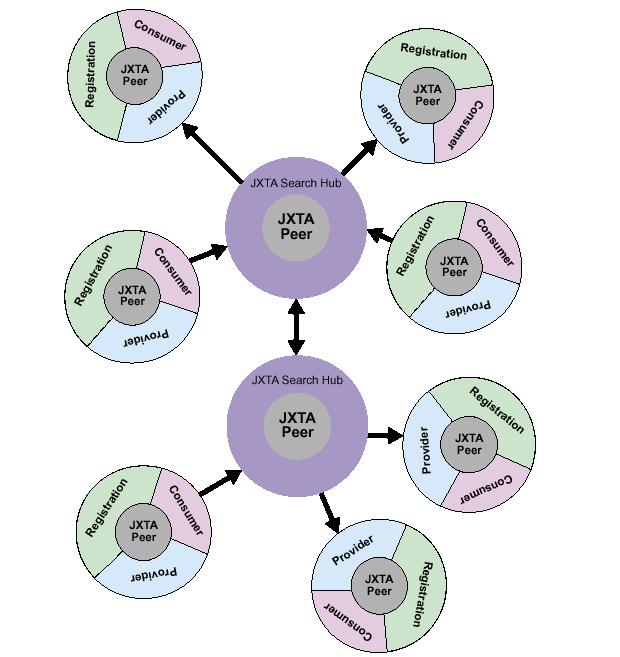
図3: 分散したJXTA Searchでは、ネットワーク内のそれぞれのピアは適切なサービスを用いてハブと相互動作する。
問い合わせ空間(queryspace)とは、問い合わせが移動する抽象的な空間に対する一意な識別子である。問い合わせ空間はJXTA Searchフレームワークの基本的なコンポーネントである。XML名前空間に似て、問い合わせ空間は一意なURIによって同定される。XML名前空間のURIのように、問い合わせ空間のURIは必ずしも実際のコンテンツを参照しない。それらはプロバイダやコンシューマがお互いを見つけるために使う、単なる識別子である。
JXTA Searchプロトコルは問い合わせ空間の構文や意味について何も仮定していない。JXTA Searchは現在は問い合わせ空間を処理せず、同様に問い合わせや応答を確認しようとすることもない。現在、問い合わせ空間はコンシューマとプロバイダの間の調整のためだけに使われる。問い合わせ空間は一般的に以下の情報を組み込むべきである。
JXTA Searchは問い合わせ空間情報を交換するための方法を指定していない。プロトコルは単に、プロバイダが自分の問い合わせ空間にマッチする問い合わせしか受信しないということを保証するだけである。しかし、それぞれの登録される問い合わせ空間に述語を含めることでプロバイダが受信する問い合わせをフィルタできるようにして、JXTA Searchは効率を高めている。述語は与えられた問い合わせ空間の中で、それぞれの問い合わせ候補に対して適用される。問い合わせ空間にマッチした問い合わせだけがプロバイダへと送信される。内部的には、JXTA Searchはルーティングを最適化するために述語を使用する。
それぞれの問い合わせは最低でも1つ、指定された問い合わせ空間に従う任意のXMLを含むことが出来る問い合わせセクション(query section)を持つべきである。さもないと、問い合わせはあらゆる情報プロバイダの述語にマッチしない傾向を持つようになって、結果として何も応答を受信しなくなってしまう。(前に述べたように、JXTA Searchは問い合わせを確認しようとしない。)もしも複数の問い合わせセクションが指定されたら、情報プロバイダは応答すべき問い合わせを選択することができる。
QRPは問い合わせ要求(query request)、問い合わせ応答(query response)そして登録(registration)という3つのコンポーネントから成っている。QRPの詳細はhttp://search.jxta.org/protocol.htmlに置かれているJXTA Searchプロトコル文書で詳しく説明されている。この文書はただ単にそれぞれのメッセージ型の例を提供する。
以下の2つの例はこの文書の残り部分を通して使われる例である。
これらの問い合わせとその応答、そしてプロバイダによって関連付けられた登録がJXTA Searchフレームワーク上でどのように実装されるかの説明について議論する。
http://search.jxta.org/text問い合わせ空間における、項JXTAに対する単純なテキスト問い合わせは以下のようになる。
<?xml version='1.0'?>
<request xmlns= http://search.jxta.org
xmlns:t= http://search.jxta.org/text
query-uuid= 1C8DAC3036A811D584AEC2C23
query-space= http://search.jxta.org/text >
<t:query>
<t:text>
sunw
</t:text>
</t:query>
</request>
問い合わせメッセージは以下のように構成される。
より複雑な例を以下に示す。
<?xml version='1.0'?>
<request id= 1C8DAC3036A811D584BEC2C63
query-space= http://bigbookseller.com/js
xmlns= http://search.jxta.org
xmlns:b= http://bigbookseller.com/JxtaSearch >
<b:query>
<b:author>
<quote>Bill Joy</quote>
</b:author>
<b:title>
Java
</b:title>
</b:query>
</request>
この例では、問い合わせ空間はhttp://bigbookseller.com/JxtaSearchとして定義されている。従ってその名前空間bはこの問い合わせ空間に対するURI、すなわち問い合わせ空間を使用するJXTA Searchメッセージのための必要条件にマッチする。この問い合わせは、名前空間bの中のauthorはBillかJoyであるか、またはそのタイトルがJavaを含むべきであるということを示している。
株相場サービス(stock quote service)が走っているJXTAピアによって回答される最初の問い合わせに対する応答は以下のようになる。
<?xml version='1.0'?>
<responses xmlns= http://search.jxta.org
xmlns:t= http://search.jxta.org/tickerqs
query-uuid= 1C8DAC3036A811D584AEC2C23 >
<response>
<data>
<t:ticker>
SUNW
</t:ticker>
<t:price>
20.59
</t:price>
</data>
</response>
</responses>
応答メッセージは以下のように構成される。
プロバイダはネットワーク内のどのピアもなることができて、これにはJXTA Searchサービスプラグインを実行するJXTAピアや、QRPに適合されたHTTPピアがある。
2番目のメッセージに対する応答は以下のようになる。
<?xml version='1.0'?>
<responses xmlns= http://search.jxta.org
xmlns:b= http://bigbookseller.com/JxtaSearch
query-uuid= 1C8DAC3036A811D584BCC2C23 >
<response>
<data>
<b:author>
Bill Joy, Guy Steel, James Gosling, Gilad Bracha
</b:author>
<b:URL>
http://www.bigbookseller.com/0201310082
</b:URL>
<b:title>
The Java Language Specification, Second Edition (The Java Series)
</b:title>
<b:price>
$39.95
</b:price>
<b:abstract>
A definitive technical reference for the Java programming
language, written by the inventors of the technology.
</b:abstract>
</data>
</response>
</responses>
情報プロバイダはJXTA Searchネットワークに登録しなければならない。登録のために、プロバイダは登録メッセージを使ってアクセスポイントに接触する。登録メッセージは以下の3つのコンポーネントを持つXML文書である。
登録は、プロバイダが公開したい情報についてのメタデータを含むXML文書である。登録は以下のタグを含まなければならない。
<register>...</register>
<predicate>...</predicate>
述語はそのプロバイダが関係する問い合わせの構造と内容を定義する。次の節では述語を形成するためのルールとリゾルバの実装について記述する。
あるプロバイダに対する以下の登録ファイルを考える。
<?xml version='1.0'?>
<register xmlns= http://search.jxta.org >
<title>JXTA Stock Quote Provider</title>
<link>http://search.jxta.org</link>
<description>Given a ticker symbol, returns a 15-minute delayed quote
</description>
<query-server>jxta://
59616261646162614A757874614D5047CF403C5700D44AE68F9FB626DD3F18E500000000
00000000000000000000000000000000000000000000000000000401</query-server>
<query-space uri="http://search.jxta.org/text">
<predicate>
<query>
<text>sunw aol orcl</text>
</query>
</predicate>
</query-space>
</register>
登録は以下のように構成される。
ウェブ上で実際に使われている登録の例としては、O'ReillyのMeerkatサービスが最近JXTA Searchサービスに対応している。以下に示すのはその登録の例である(これらはsearch.jxta.org/text空間にある全ての問い合わせに対して登録している)。
<?xml version='1.0'?>
<register xmlns= http://search.jxta.org >
<title>O'Reilly Network</title>
<link>http://meerkat.oreillynet.com/</link>
<description>
The Source for Open and Emerging Technologies.
</description>
<image>
<url>http://meerkat.oreillynet.com/icons/meerkat-powered.jpg</url>
<width>88</width>
<height>31</height>
</image>
<query-server>http://www.oreillynet.com/meerkat/jxtasearch/</query-server>
<query-space uri="http://search.jxta.org/text">
<predicate>
<query>
<text>
< /text>
</query>
</predicate>
</query-space>
</register>
問い合わせ解決とは、与えられた問い合わせをルーティングすべきプロバイダの集合を決めるためのプロセスである。明らかに、全ての問い合わせを全てのプロバイダに送信するというのは非効率的である。そのため、JXTA Searchは以下のことによって効率をより高めようとしている。
問い合わせをプロバイダにマッチさせるための最低条件は、問い合わせがプロバイダ登録と同じ問い合わせ空間を持たなければならないということである。プロバイダの集合は以下の順番でリゾルバによって選択される。
プロバイダは自分が受信したい問い合わせの形式を自らの登録ファイルの中で指定すると思われる。このファイルはその形式を、問い合わせの構造や問い合わせ空間、そのプロバイダが受け取る関係を持つ応答のフォーマットにエンコードする。このファイルはプロバイダのメタデータとその構造についての通知(advertisement)として考えることができる。登録ファイルは以下のものを指定する。
前に述べたbigbookseller.comの例で使われる可能性のある以下の登録を考える。
<?xml version='1.0'?>
<register xmlns="http://search.jxta.org"
xmlns:b= http://bigbookseller.com/jxtasearch >
<query-server>
http://bigbookseller.com/exec/jxtasearch.pl
</query-server>
<query-space uri= http://bigbookseller.com/jxtasearch >
<predicate>
<query>
<b:author>
<quote>Bill Joy</quote><quote>Neal Stephenson</quote>
</b:author>
<b:title>
Java JXTA XML Cryptography
</b:title>
</query>
</predicate>
</query-space>
</register>
これはhttp://bigbookseller.com/jxtasearchによって指定されたテキスト問い合わせ空間を使ってプロバイダを登録する。この登録は以下の問い合わせに対してプロバイダを登録する。
これらの条件にマッチする問い合わせはhttp://bigbookseller.com/exec/jxtasearch.plで動作している問い合わせサーバへと差し向けられる。実際は述語はもっと大きくて、典型的により複雑な構造を持っている。
問い合わせノードパターンは問い合わせに対して述語をマッチさせるために使われる。それぞれの問い合わせはQNPの連続へと広げられる。
問い合わせノードパターン(QNP)は、登録の中で問い合わせ述語の基本的な構成ブロックを形成するXMLフラグメント(fragment)である。この実装では、QNPは登録述語の構造を制限する。それぞれのQNPはXML問い合わせのノードにマッチする。マッチはQNPが問い合わせの構造のある部分集合にマッチしたときに起こるか、または、より形式的には、一連の以下の変形(transformations)によってQNPが組み立てられることができたときに起こる。変形とは「1)問い合わせの中のノードを削除する」または「2)問い合わせをその部分ノードと置き換える」ことである。
例えば、以下の問い合わせを考える。
<request>
<object type=file>
<format>jpeg</format>
<desc>foo bar</desc>
</object>
</request>
この問い合わせは表1で示されるQNPによってマッチされる。
| QNP | 以下のノードを持つ問い合わせにマッチする |
|---|---|
| <object></object> | OBJECTノード |
| <object type=file></object> | パラメータTYPE=fileを持つOBJECTノード |
| <format>jpeg</format> | テキスト内にjpegを含むFORMATノード |
| <object><format></format></object> | FORMATノードを含んでいるOBJECTノード |
| <object><desc>foo bar</desc></object> | fooかbarを含むdescノードを含んでいるOBJECTノード |
表1: QNPマッチング
QNPは以下の制限を含んでいる。
<object>
<format>jpeg</format>
<desc>foo</desc>
</object>
この無効な登録は(上に示されたものの)代わりに、以下のようにして2つの分離したQNPの論理積(conjunction)を含む述語として指定されなければならない。
<and>
<object>
<format>jpeg</format>
</object>
<object>
<desc>foo</desc>
</object>
</and>
タグテキストは単一パス制限の例外である。もしもあるQNPノードが複数のテキストトークンを含んでいたら、トークンは暗黙的に分離する(脚注2:これは自動的に行われるだろう。しかし、いくつかの場合には述語のサイズがかなり増えてしまうかもしれない。現在は、プロバイダがより小さくて速い述語を組み立てるようになることを促進しようと努力しているので、この分離は自動的には行われない。この制限によって、述語の効率はそのサイズに比例している。)。例えば、以下のXMLは有効な登録である。
<object>
<format>jpeg gif png</format>
</object>
問い合わせ述語はQNPから構成された論理式(boolean expression)である。述語はconjunctive normal form(和積標準形)、すなわち論理和(disjunction)の論理積の中になければならない(脚注3:この制限は将来取り除かれるかもしれない。)。
以下の問い合わせ述語を考える。
<predicate>
<and>
<object type=file>
<object><format>jpeg</format></object>
<or>
<desc>bar</desc>
</or>
</and>
</predicate>
最初の2つ(のOBJECTノード)の接続詞(conjunct)は暗黙に論理和であることに注意すること。<or>...</or>タグが単一のQNPのみを含む場合は、<or>...</or>は削除してもよい。同様に、一番上のレベルが1つしか要素を持たないならば、<and>...</and>も削除してよい。従って一番単純な場合には、述語は<predicate>foo bar</predicate>という、単語fooか単語barを含む任意の問い合わせにマッチする形式からなることができる。
リゾルバの実装はフルテキストサーチエンジンに似ている。Lucene(http://lucene.com)におけるDoug Cuttingの作業に感化されて、リゾルバは登録ファイル中の全てのタグとテキストを索引付けする。問い合わせ項をプロバイダへと対応させる逆索引が作られる。効率のために、リゾルバはそれぞれの問い合わせ空間ごとに異なる目次(indice)を作成する。
リゾルバは目次の集合から成っていて、それぞれの問い合わせ空間に対して1つの目次が存在する。プロバイダが登録ファイルを送信すると、リゾルバはそれを述語の集合へと構文解析する。それぞれの述語は節の集合を持ち、そしてそのそれぞれの節は論理和の集合を持つ(脚注:現在、述語は和積標準形の中にあるように制限されている。)それぞれの述語は世界的に一意な述語IDを割り当てられて、それぞれの節はローカルな節IDを割り当てられる。登録の中のそれぞれのパターンに対して、その述語IDと節IDを格納したポスティング(posting)が作られる。述語IDと節IDは登録の中にある節へのパターンを追跡するために使われ、その登録はパターンが存在するものである。パターン/ポスティングのペアはそれに相当する問い合わせ空間の索引の中に格納される。ポスティングはまた、ユーザから受信したフィードバックに基づいて更新される得点(score)も格納する。(プロバイダの得点付けはこの文書の後の方で議論されている。)
以下に示すものは、登録とそれに相当する索引エントリの中の2つの述語の単純なXMLフラグメントの例である。
<predicate>
<and>
<object type=pics>
<object><format>jpeg</format></object>
<or>
<desc>foo</desc>
<desc>bar</desc>
</or>
</and>
</predicate>
<predicate>
<and>
<object type=recipes>
<object><format>recipes</format></object>
<or>
<title><quote>Rhubarb Pies</quote></title>
<title><quote>Scrambled Eggs</quote></title>
</or>
</and>
</predicate>
索引は8つのエントリを含んでいる。これらのエントリの少なくとも3つは、問い合わせがプロバイダへとルーティングされるために、問い合わせにマッチしなければならない。以下がそれに相当する索引エントリである。
object&type=pics (predicate0, clause0)
object>format>jpeg (predicate0, clause1)
desc>foo (predicate0, clause2)
desc>bar (predicate0, clause2)
object&type=recipes (predicate1, clause0)
object>format>recipes (predicate1, clause1)
title>Rhubarb Pies (predicate1, clause2)
title>Scrambled Eggs (predicate1, clause2)
前に述べられたように、得点はリゾルバの索引中のそれぞれのパターン/ポスティングペアに関係付けられている。得点付けはあるタイプの問い合わせに対するプロバイダの一般性(popularity)を決定するために使われる。得点付けはリゾルバの本質的な部分ではないが、しかしもし存在すれば、その問い合わせに関係する最も一般的なプロバイダを選択するのを助ける。
得点付けは以下のように働く。もしもユーザが問い合わせ応答への応答の中でフィードバックを送信したら、その問い合わせにマッチしたパターン/ポスティングペアが対応する問い合わせ空間索引から回収されて、その得点が更新される。(得点は正のフィードバックによって増やされるか、負のフィードバックによって減らされる。)現在のJXTA Search実装では単純な得点更新式が使われているが、しかしより複雑なアルゴリズムも考えることができる。以下に示すのが使用される式で、(0 < alpha < 1)が得点の変化する割合を決定する。
Score(t+1) = (alpha) * Score(t) + (1 - alpha) * Feedback
ある問い合わせにマッチするプロバイダが非常に少ない場合には、JXTA Searchは、その問い合わせにはマッチしないが、同じ問い合わせ空間を登録していてなおかつその問い合わせにマッチしたプロバイダに似ている、そんなプロバイダを選択するかもしれない。
協調フィルタリング(collaborative filtering)に似た概念がプロバイダの類似性を決定するのに使われる。本質的に、同じ問い合わせにマッチする傾向があるプロバイダ同士はより似ていると見なされる。現在のJXTA Search実装はリゾルバ内部に類似性行列(similarity matrix)を維持している。
ルータは以下の機能を実行する。
ルータがネットワークから要求を受け取ると、ルータはリゾルバに対して、この要求に似た問い合わせを受信することを求めるものとして登録されているネットワーク上のノードのリストを要求する。リゾルバがネットワークノードエンドポイントとネットワークノードIDの集合を返すと、ルータはそのプロバイダの集合へと問い合わせをルーティングする。
メッセージが集中してホストが遅くなったり(=spamming slow)一時的にホストが落ちるのを防ぐために、ルータは指数的な一時待避アルゴリズム(exponential back-off algorithm)を使用する。もしもプロバイダが決まったタイムアウト(set timeout)を越えたら、リゾルバサブシステムは「このプロバイダは非アクティブかもしれないので、これ以降の解決はこのプロバイダを含むべきではない」ということを警告されている。
JXTAネットワークに対して、ルータは以下のように動作する。
JXTAルータは以下のようないくつかのコンポーネントを持っている。
JXTAピアから要求を受け取るコンポーネントは、問い合わせ要求のための入力パイプを単純にlistenする。問い合わせ要求が到着すると、リゾルバはその問い合わせを渡すべきピアの集合を決定する。もしもそのピアがJXTAに基づくピアならば、JXTAルータはそのピアの入力パイプへと向かう出力パイプを通して要求を送信する。JXTAルータは1つの入力パイプを、JXTAピア群から送られてくる問い合わせ応答を受信するための専用のパイプにする。要求を開始したピアへと応答群を一斉に送り返すための十分な条件が満たされたら、JXTAルータは要求ピアへと(1つの)問い合わせ応答メッセージを送信する。
HTTPネットワークに対して、ルータは以下のように動作する。
効率を高めるべく、HTTPルータは既に問い合わされた各々のプロバイダへの接続を維持するためにKEEP_ALIVEも使用する。このプロバイダへの複数の要求は単一の接続上で作られる。これは与えられたプロバイダに対する要求のキューを記憶しておくためである。その目的はプロバイダへの接続を繰り返し開いたり閉じたりするのを防ぐことである。この方法が単純なアプローチによって実質的なパフォーマンスの改善を提供することは経験が示している。
上で示したように、JXTA Searchはネットワークやメッセージのフォーマットには拘らない(network and message format agnostic)。現在はJXTAバインディングとウェブ・バインディングという、2つのプラットフォーム・バインディングがサポートされている。
JXTAパイプは問い合わせ要求、問い合わせ応答、そして登録のメッセージを運ぶための単純な方法を提供する。JXTA SearchのQRPプロトコルスイートは素直なやり方でJXTAパイプと対応させることができる。それぞれの場合に、JXTA SearchメッセージはJXTAメッセージの中に封入される。
問い合わせ要求メッセージに対して、JXTAメッセージは2つのタグ/値ペアを持つ。これはrequestとresponsePipeで、実際の問い合わせ要求メッセージはrequestタグの値として格納される。ピアが応答を受け取るのに使いたいパイプのためのパイプ通知(pipe advertisement)はresponsePipeタグの値として格納される。出力パイプを使って、ピアは問い合わせ応答JXTAメッセージ(訳注:問い合わせ要求JXTAメッセージの間違いだと思われる)をJXTA Searchピアの入力パイプへと届ける。
問い合わせ応答メッセージは唯一のタグ/値ペアであるresponsesを持つ。JXTA Searchピアが問い合わせ要求に対する回答を手にいれると、そのピアは問い合わせ要求メッセージのresponsePipeタグの中で指定されたパイプへと出力パイプを開いて、responsesタグの中を応答で一杯にした問い合わせ応答JXTAメッセージを送信する。
登録メッセージは2つのタグ/値ペアを持つ。これはregistrationとresponsePipeで、登録文書はregistrationタグの中に格納される。ピアが応答を受け取るのに使いたいパイプのためのパイプ通知(pipe advertisement)はresponsePipeタグの値として格納される。出力パイプを使って、ピアはこのメッセージをJXTA Searchハブへと送信する。応答を受信したピアはその登録を処理して、成功か失敗のコードを登録メッセージ内のresponsePipeタグで指定されたパイプへと送り返す。
JXTA Searchネットワークは現在JXTAだけでなくHTTPトランスポート上でも実装されている。HTTPを用いて、問い合わせ要求は要求を処理するプロバイダアダプタへのHTTP postとして送信される。例えば、以下に示すものはアダプタJxtaSearch.jspへと問い合わせメッセージをpostする。
POST /JxtaSearch.jsp HTTP/1.0 Content-Type: text/xml <?xml version='1.0'?> ....
問い合わせはHTTPによってプロバイダへと送信される。POST要求が使われる。要求のcontent typeはtext/xmlである。要求のボディは問い合わせ、すなわちXML文書を格納している。
エンドユーザやアプリケーションによって問い合わせられるように設計されているにも関わらず、JXTA Searchはプロバイダに問い合わせてその応答を表示するウェブフロントエンドに焦点を合わせたコンシューマも提供する。このフロントエンドは以下の機能を実行する。
JXTA Searchは、一般的なアプリケーションでの問い合わせルーティングのためのネットワークプロトコルとフレームワークとして意図されている。JXTAハブとHTTPハブという2つのリファレンス実装が存在して、これらはJXTAネットワークとウェブネットワークでの使用を意図されている。現在はこれらのドメインに対して2つのアプリケーションが存在する。それは単純なJXTA情報プロバイダとコンシューマ、そして、JXTA Search HTTPハブへと問い合わせを送信するコンシューマのように振る舞うウェブサイトである。動作例はhttp://search.jxta.org/demo(訳注:現在このサイトは存在しない)を参照のこと。
もしも将来のJXTA情報プロバイダの動作をシミュレートするならば、その1つの例はJXTAピア上での株相場サーバの実装である。このサーバは問い合わせを受け取るとYahoo!financeに接続して、ウェブサイトからの結果を解析する。将来、このサーバはYahooやその他のプロバイダに置かれたJXTAピア上に実装されるかもしれない。この例では、JXTAピアはNYSE、NASDAQそしてAMEX取引所での全ての銘柄に対して登録を行い、ウェブ検索クライアントによって理解されるフォーマットの中の標準のhttp://search.jxta.org/text問い合わせ空間の要求に対して応答する。
例のウェブ検索クライアントはサーブレットとJSPの実装を使用し、標準的なウェブサーチエンジンに似ている。ウェブクライアントはhttp://search.jxta.org/text問い合わせ空間の中の問い合わせを送信して、http://search.jxta.org/protocol.htmlに置かれているプロトコル仕様で記述されている単純なXMLフォーマットに従う応答を期待する。このウェブクライアントはHTML内の項目のリストとして受け取った結果の体裁を整える。
ウェブ上でのJXTA Searchの可能性を証明するために、このウェブクライアントはある決まったウェブ検索インターフェイスのフォーマットを理解するプロキシエンジンも含んでいる。その結果、JXTA Searchアダプタがまだ動作していないある特定のサイトに対して、問い合わせや応答を送受信することができる。
加えてこのウェブクライアントは、プロバイダがサインアップして登録を監視したり、ユーザがハブへとある優先権を送信するためのユーティリティを含んでいる。
JXTA Searchは分散ネットワーク内での問い合わせルーティングのための斬新なアプローチである。強力だが単純な索引付けマッチングエンジンと結び付けられた単純なXMLプロトコルを使うことにより、JXTA Searchは開発者に対して、情報の探索と交換を目的とした複数のコンシューマとプロバイダのアプリケーション間の相互接続の能力を提供する。JXTAやpredominance of Webやその他のネットワークサービスのような分散ネットワークの成長に伴って、JXTA Searchのような柔軟なソリューションに対する必要性は増加すると我々は予想している。
以下のものを含むいくつかのアプリケーションは分散検索モデルに役立つ。
JXTA Searchは現在Sun JXTAライセンスの元でオープンソースソフトウェアとして利用できる。Sunはデベロッパとユーザがコードベースをダウンロードして、使って、拡張するのを促進し、JXTA Searchネットワークを試験利用すること(foster use)を促進している。
JXTA Searchを拡張するためのさまざまな機会がある。これは以下のものを含む。
ソースコードや文書、メーリングリスト、サンプルのデモを含むこれ以上の情報はhttp://search.jxta.orgにあるJXTA Searchメインウェブサイトで見つけることができる。
最初に、JXTA Searchエンジニアリングチーム全体、John Beatty, Sherif Botros, Tom Camarda, David Doolin, Yaroslav Faybishenko, Gene KanそしてCody Oliverに感謝したい。また私はJXTAエンジニアリングチーム、特にLi Gongの有益なフィードバックに感謝したい。またJXTA SearchチームはMark Andreessen, Doug Cutting, Rael Dornfest, David Galbraith, Spencer KimballとGraham Spencerの価値ある貢献に感謝したい。