") 書く英語・基礎編(松本 亨)
書く英語・基礎編(松本 亨)") キャズム(ジェフリー・ムーア)
キャズム(ジェフリー・ムーア)![Google App Engine for Java [実践]クラウドシステム構築 (WEB+DB PRESS plus) (WEB+DB PRESSプラスシリーズ) (WEB+DB PRESS plusシリーズ)((株)グルージェント)](http://ecx.images-amazon.com/images/I/51S5E3PHJFL._SL160_.jpg "Google App Engine for Java [実践]クラウドシステム構築 (WEB+DB PRESS plus) (WEB+DB PRESSプラスシリーズ) (WEB+DB PRESS plusシリーズ)((株)グルージェント)") Google App Engine for Java [実践]クラウドシステム構築 (WEB+DB PRESS plus) (WEB+DB PRESSプラスシリーズ) (WEB+DB PRESS plusシリーズ)((株)グルージェント)
Google App Engine for Java [実践]クラウドシステム構築 (WEB+DB PRESS plus) (WEB+DB PRESSプラスシリーズ) (WEB+DB PRESS plusシリーズ)((株)グルージェント) muziyoshiz.jpまでどうぞ。
muziyoshiz.jpまでどうぞ。
2015/03/15
■最近の活動について
こちらのサイトでのブログ記事の更新は、ひとまず凍結しました。今後は複数のサービスを使い分ける形で情報発信したいと思います。
ある程度まとまったメモは、はてなブログで公開していきます。
http://muziyoshiz.hatenablog.com/
職場ブログでも、DevOps担当のM.Y.名義で記事を書いてますので、こちらもどうぞ。
http://recruit.gmo.jp/engineer/jisedai/blog/
[ツッコミを入れる]
2010/03/02
■[programming]Google DevFest 2010 Japan Quizの問題とその答えの一例(Rubyで解きました)
これまでのあらすじ:
3/18(木)に開催されるGoogle DevFest 2010の募集がかけられた。参加したらNexus Oneがただで貰えるのではないかと見込んだ(僕みたいな)応募者が殺到したせいかどうかは知らないが、参加希望者は定員の400名をオーバーしていた。そこで、参加希望者を上位400名に絞り込むためのプログラミングクイズがGoogleから参加希望者に送りつけられ、Nexus Oneに釣られた参加希望者はそれを嬉々として解いてしまうのだった。Nexus Oneなんて配られないとも知らずに……。
----
そんなDevFest Quizも終わり、採点結果が参加希望者に送られたようなので、せっかくだから僕の答えも公開してみます。まあ、基本的に問題文通りの処理をベタ書きしただけですけど。
DevFest Quizは全部で10問出題され、プログラミングの問題は以下の3題でした。androidzaurusさんによる以下のまとめを見ると、みんな思い思いの言語で解いたみたいですね。僕はRubyで解きました。
みんなの回答のまとめ:はてなブックマーク - 安藤恐竜のブックマーク - DevFestQuiz
----
■ 暗号通信(配点:4.0点)
あなたの登録したメールアドレスを、このクイズサーバーに転送して下さい。 ただし、次のような暗号化をしてください。
- A → L
- B → M
- C → N
- D → O
- E → P
- 中略 → 中略
- Z → K
- a → l
- b → m
- c → n
- 中略 → 中略
- z → k
- @ → @
- 1 → 1
変換したメールアドレスと、次のキーワード : "(省略)" とを一緒に、http://devquiz.appspot.com/personalpost までpostしてください。 二つのデータは以下のようにjson形式にして、POSTの本文に text/plain 形式で入れてください。
{ "key": キーワード "pass": 変換されたメールアドレス }
この問題は、自分のメールアドレスを変換するところまではRubyでプログラムを書いたのですが、データをpostするところはFirefoxアドオンのRestTestで送りつけて済ませちゃいました。
メールアドレスの変換処理は以下のようにベタに書いたんですが、他の人の答えを見てると、Rubyだったらtrっていうメソッドを使うと楽に解けたみたいです。なんでみんなそんなの知ってるの……と思ったらPerl由来なんだそうで。なるほど。
email = "メールアドレス"
BEFORE = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz@.1234567890"
AFTER = "LMNOPQRSTUVWXYZABCDEFGHIJKlmnopqrstuvwxyzabcdefghijk@.1234567890"
converted_email = ""
email.split("").each do |str|
regex = Regexp.new(Regexp.escape(str))
idx = (BEFORE =~ regex)
converted_email += AFTER[idx, 1]
end
print converted_email
----
■ パッチワーク(配点:5.0点)
ここ(実際はテキストファイルへのリンク)に "A" または "B" という文字のみを含む 600 桁、600 行のテキストがあります。 これを 600 x 600 の升目状に並べ、上下左右に同じ文字がある部分をつながっているとみなします。
まず、最も多くの文字がつながっている領域をすべて "_" で塗りつぶしてください。 最も多くの文字がつながっている領域が複数存在するならば、それらすべての領域を "_"で塗りつぶすこととします。
そして、各行ごとに "_" が何個含まれているかを数え、それらの数値を改行区切りのテキスト(600 行)として答えてください。
以下の例1を見てください。この入力には単一の文字4つでつながった領域が3箇所あります。これらすべてが「最も多くの文字がつながっている領域」なので、全て"_"で塗りつぶし、その数を数えています。
例1:
入力ABAAB BABAA BAABB ABABB BABAA塗りつぶしたところ.
AB__B B_B__ B____ AB___ BABAA答え
2 3 4 3 0例2:
入力AAABABAAAA ABBBBBABAA BAABAAABAA BBAABABABA BAABBAAABA AABABAABAB ABAABBABAB BABBBABABB BABABBAABB BBBABABAAA塗りつぶしたところ.
AAABAB____ ABBBBB_B__ BAAB___B__ BBAAB_B_B_ BAABB___B_ AABAB__BAB ABAABB_BAB BABBBABABB BABABBAABB BBBABABAAA答え
4 3 5 3 4 2 1 0 0 0
これは、最初なにかエレガントな解決方法があるんじゃないかと色々試したんですが、処理にやたら時間がかかったり、結局正解が出なかったりしました……。なので、結局以下のようにいちいち探索する処理を書いて解きました。
それぞれの動作は、ソースコード中のコメントの通りです。読んでもわかりにくいところとしては、check_groupメソッドがインスタンス変数@input_arrayやら@checked_arrayを参照してるところでしょうか。上から順に処理を書いていったらこうなったんですが、正直かなり汚いコードですね、こりゃ。
# 問題の読み込み
@input = []
open("patchworkinput.txt") {|file|
while line = file.gets
@input << line.chomp
end
}
# 幅と高さ(これは不要だったかも)
@width = @input.first.size
@height = @input.size
# 読み込んだ値を入れる二次元配列
# Aなら0、Bなら1とする
@input_array = []
A = 0
B = 1
# それぞれの値をチェック済みか記録する二次元配列
# チェック前なら0、チェック済みなら1とする
@checked_array = []
UNCHECKED = 0
CHECKED = 1
# 二次元配列に初期値を設定
@input.each_with_index do |line, y|
line.split("").each_with_index do |c, x|
@input_array[y] ||= []
@input_array[y][x] = (c == "A" ? A : B)
@checked_array[y] ||= []
@checked_array[y][x] = UNCHECKED
end
end
# 個々の点を始点として、再帰的に値をチェックするための関数
# 返り値として、マッチした文字の数を返す
# xは横軸、yは縦軸の座標(いずれも0開始)、valueはマッチすべき値(AまたはB)
def check_group(x, y, value)
# 座標が枠外なら0を返す
return 0 if x < 0 or y < 0 or x >= @width or y >= @height
# その枠が既にチェックされていたら0を返す
return 0 if @checked_array[y][x] == CHECKED
# その枠の値がvalueと違ったら0を返す
return 0 unless @input_array[y][x] == value
# その枠の値がvalueと同じだったら、チェックを入れる
@checked_array[y][x] = CHECKED
# 上下左右を再帰的にチェックする
1 + check_group(x - 1, y, value) + check_group(x + 1, y, value) +
check_group(x, y - 1, value) + check_group(x, y + 1, value)
end
# [ チェックに使った始点x軸, 始点y軸, 値, 一致した要素の数 ] の配列を格納する変数
results = []
@input_array.each_with_index do |line, y|
line.each_with_index do |value, x|
# その枠が既にチェックされていたらパス
next if @checked_array[y][x] == CHECKED
results << [ x, y, value, check_group(x, y, value) ]
end
end
# 一致した要素の数の最大値を計算
max_num = 0
results.each do |res|
max_num = res[3] if max_num < res[3]
end
# 一致した要素の数が最大のものだけを選択
max_results = results.select{|res| max_num == res[3] }
# 二次元配列をすべてリセット
@input_array = []
@checked_array = []
@input.each_with_index do |line, y|
next if y >= @height
line.split("").each_with_index do |c, x|
next if x >= @width
@input_array[y] ||= []
@input_array[y][x] = (c == "A" ? A : B)
@checked_array[y] ||= []
@checked_array[y][x] = UNCHECKED
end
end
# 今度は、正解部分だけをチェックする
max_results.each do |res|
check_group(res[0], res[1], res[2])
end
# 各行の正解数を数えて、ファイルに書き込む
open("result.txt", "w") do |f|
@checked_array.each do |line|
f.puts line.select{|l| l == CHECKED }.size
end
end
----
■ 漢字変換サーバ(配点:7.0点)
数字を漢数字に変換するアプリケーションを作ってください。
http://[あなたのアプリケーションのURL]?n=[数字] にアクセスすると、 text/plain でその数字を漢数字に変換した結果を返すウェブサーバを作ってください。 ただし、漢字はすべて以下の表の通りにアルファベットに変換して出力してください。
- 零 → K
- 一 → E
- 二 → Y
- 三 → M
- 四 → B
- 五 → H
- 六 → P
- 七 → Z
- 八 → N
- 九 → J
- 十 → X
- 百 → G
- 千 → F
- 万 → U
- 億 → T
- 兆 → L
注意:
- 「千万」「千億」「千兆」の前に「一」がつかないようにしてください。
- 入力は負でない整数で、大きさは高々9999兆9999億9999万9999までです。
- 標準のポート番号80番のみ扱えます。
僕が問題を解いたときは「一」に関する注意書きがなかったような気がするんですが、ミスする人が多かったんですかね。気持ちは分かります。
それで回答の方針ですが、僕は数字を漢数字に変換するKanjiクラスを作って、それを呼び出す形にしました。テストケースを書きたかったというのもあって、変換処理は独立したクラスとして実装しています。
まず、Kanjiクラスを呼び出すnk_application.rb。このファイルに実行権を与えて公開します。
#!/usr/bin/env ruby require "cgi-lib" require "kanji" input = CGI.new print "Content-type: text/plain\n\n" str = Kanji.num2kanji(input["n"]) print str if str
次に、Kanjiクラスを実装したkanji.rb。かなりベタベタにかいてます。
class Kanji
def self.num2kanji(number)
# 数字以外は無視
unless number =~ /^\d+$/
return nil
end
# 京に達してたら無視
if number.size > 16
return nil
end
# 値が0の時は、零 → K を返す
if number.to_i == 0
return "K"
end
# 数字を後ろから4個ずつの固まり(チャンク)に区切る
numbers = []
# 部分文字列を作るためのインデックスと長さ
index = number.size
length = 4
while index > 0
if index < 4
length = index
index = 0
else
index = index - 4
end
numbers << number[index, length]
end
# 下の位から取っているので、順序を入れ替える
numbers.reverse!
# 返り値
kanji = ""
numbers.each_with_index do |fournum, i|
# 数値に変換してゼロだったら何もしない
next if fournum.to_i == 0
kanji += fournum2kanji(fournum)
case numbers.size - i
when 4
# 兆 → L
kanji += "L"
when 3
# 億 → T
kanji += "T"
when 2
# 万 → U
kanji += "U"
end
end
kanji
end
# 零が出てくるのは0のときだけと思われるので、それは無視する
# (0だけは例外として、もっと手前で扱う)
BEFORE = "123456789"
AFTER = "EYMBHPZNJ"
# 4文字の数字を、何千何百何十何、まで変換して返します。
def self.fournum2kanji(fournum)
kanji = ""
fournum.split("").each_with_index do |num, i|
regex = Regexp.new(Regexp.escape(num))
idx = (BEFORE =~ regex)
if idx
case fournum.size - i
when 4
# 千 → F
# 1だけ特別扱い(一千、とは言わない)
kanji += AFTER[idx, 1] unless num == "1"
kanji += "F"
when 3
# 百 → G
# 1だけ特別扱い(一百、とは言わない)
kanji += AFTER[idx, 1] unless num == "1"
kanji += "G"
when 2
# 十 → X
# 1だけ特別扱い(一十、とは言わない)
kanji += AFTER[idx, 1] unless num == "1"
kanji += "X"
when 1
kanji += AFTER[idx, 1]
end
end
end
kanji
end
end
で、最後に「一千」とかの扱いに不安があったので、このKanjiクラスをテストするkanji_test.rbも書きました。
require 'test/unit'
require 'kanji'
class TestKanji < Test::Unit::TestCase
def setup
end
def teardown
end
def test_num2kanji
# 零 → K
# 一 → E
# 二 → Y
# 三 → M
# 四 → B
# 五 → H
# 六 → P
# 七 → Z
# 八 → N
# 九 → J
# 十 → X
assert_equal("K", Kanji.num2kanji("0"))
assert_equal("E", Kanji.num2kanji("1"))
assert_equal("Y", Kanji.num2kanji("2"))
assert_equal("M", Kanji.num2kanji("3"))
assert_equal("B", Kanji.num2kanji("4"))
assert_equal("H", Kanji.num2kanji("5"))
assert_equal("P", Kanji.num2kanji("6"))
assert_equal("Z", Kanji.num2kanji("7"))
assert_equal("N", Kanji.num2kanji("8"))
assert_equal("J", Kanji.num2kanji("9"))
assert_equal("X", Kanji.num2kanji("10"))
# 九十九
assert_equal("JXJ", Kanji.num2kanji("99"))
# 百 → G
assert_equal("G", Kanji.num2kanji("100"))
# 百一
assert_equal("GE", Kanji.num2kanji("101"))
# 九百九十九
assert_equal("JGJXJ", Kanji.num2kanji("999"))
# 千 → F
# 1000 は 千
assert_equal("F", Kanji.num2kanji("1000"))
# 千一
assert_equal("FE", Kanji.num2kanji("1001"))
# 千十
assert_equal("FX", Kanji.num2kanji("1010"))
# 万 → U
# 1万 は 一万
assert_equal("EU", Kanji.num2kanji("10000"))
# 億 → T
# 1億 は 一億
assert_equal("ET", Kanji.num2kanji("100000000"))
# 兆 → L
# 1兆 は 一兆
assert_equal("EL", Kanji.num2kanji("1000000000000"))
# 9999兆9999億9999万9999
assert_equal("JFJGJXJLJFJGJXJTJFJGJXJUJFJGJXJ", Kanji.num2kanji("9999999999999999"))
# この範囲を超えたらエラー
assert_equal(nil, Kanji.num2kanji("10000000000000000"))
end
end
動作中のサンプルはこちら:http://muziyoshiz.jp/archives/devfest2010/nk_application.rb
----
僕の答えはこんな感じだったのですが、いかがでしたでしょうか。何か(物笑いとか)のネタになれば幸いです。
[ツッコミを入れる]
2010/01/04
■[P2P]2009年の無印吉澤と吉澤を振り返る
あけましておめでとうございます。今年も皆様よろしくお願いします。
今日の日記は、年末年始恒例の一年を振り返る日記(いわゆる反省会)です。昨年までの反省会はこちら(↓)。
----
■ 2009年の無印吉澤を振り返って
数えてみたら、去年は12回しか日記書いてませんでした。そのうち5回は単なるP2P SIP勉強会の告知なので、実質7回。
色々理由はあると思うのですが、その一つとしては、ちょっとした感想くらいならtwitterでつぶやいて満足してしまうようになったのが原因かもしれません。ちなみに、去年までtwitterはprotectedで使っていたのですが、今年の5月くらいからpublicにして使うようになって、そこから一気に100人以上followerが増えた一年でした。
日記を書くペースは年々落ちる一方ですが、最近はもう(後述の理由も含めて)仕方ないと自分では諦めました。諦めましたけど、面白い本を読んだり、新しい技術に触れたりして、ネタが出来たときは今後も随時ここに書いていこうと思います。
2009年の読書ネタ(7月以降に読んだ本についてもそのうち……)
2009年の新しい技術ネタ(Androidアプリの機能追加ネタもそのうち……)
- 自作Androidアプリ「Where's My Info?」をAndroid Marketに登録してみました
- RDBからGoogle App Engineのデータストアに乗り換えるときのつまずきポイントとか実例とか
----
■ 2009年の吉澤を振り返って
昨年は、一昨年に引き続いて仕事の忙しい一年でした。
今までは割と個人でちまちまやる仕事が多かったのですが、昨年は小さいチームのリーダ的ポジションとしてチームの回し方を考えたり、自分たちの部署の技術をよそに宣伝したり、逆によその人にインタビューしたり、色々慣れない仕事を経験させてもらいました。
その過程で気の進まない仕事をしたり、気の進まない本を読んだりする機会も多かったのですが……。結果的に、少し視野が広がって今まで気が回らなかったことにも気が回るようになったような気がしています。例えば、小さいチームでもリーダをやってみることで、自分がリーダに何を「してほしい」と思っているかをより明確に意識できるようになりました(これはあとで日記のネタにするかも)。まあ、慣れない分野に飛び出してまず経験してみることは、とても大事だなあと実感した一年でした。
その一方、慣れない仕事が続いて、家に帰ってくるとすっかり気が抜けてしまい、プライベートではなかなか新しいことに手を出せない一年でもありました。去年は読書量を増やすのが目標だったのに、夏の終わりごろからすっかり読書量が減っちゃいましたし……。
ちなみに、昨年の年末に立てた「2009年の抱負」は、以下の4つでした。
1. 週一冊は本を読む
2. 読んだ本、文献や、参加したイベントについては、必ずメモを残す
3. 英語の練習を毎日続ける
4. 新しいプログラム言語を1つ覚える
本は、読みかけの本や、つまらなくて読むのをやめてしまった本を除くと、上期に15冊、下期に10冊。2週間に1冊弱のペースですね。メモについては、日記にこそ書いてないですが、一応残しておいて後で読み返すようになりました。
英語の勉強については、ESL Podcastをほぼ毎日聞いていたのと、「書く英語 基礎編」という本(↓)でライティングの勉強を始めました。ただ、それでも2009年11月に受けたTOEICでは790点になってしまった(WritingはそのままでListeningが25点落ちた)のですが。まあ、高得点にこだわっても仕方ないので、こんなものかなと。
新しいプログラム言語については、ちょっとFlexをいじってみたくて、ActionScript 3.0をかじりました。あとは、Androidアプリを作ってみたり、Google App EngineをJavaから触ったり……ってJavaばっかりですね。いかんいかん(?)。
----
■ 2010年の抱負
今年はあまり欲張らずに、以下の3つを抱負にします。
1. 週一冊は本を読む
- 昨年は2週間に1冊弱のペースだったので、今年も引き続きこれを目標にインプットを増やします。あとは、量を急に増やすのは難しそうなので、出来るだけ「定番」とか「古典」とか言われてるような本を優先して読むようにしようと思います。
2. 読んだ本、文献や、参加したイベントについては、必ずメモを残す
- これも引き続き。出来るだけ、「他の人に話すネタ」や「他の人にアドバイスするためのロジック」の形に変えてストックしようと思い、去年から紙の日記を書いてます。まとまったら紙じゃなくてWebに書けばいいんですが、キーボードに向かうより紙に書いたほうが、僕はなぜかはかどるので……。
3. 週一回は運動する
- 去年は仕事に熱中しすぎて体調を崩すことが多く、11月の頭には新型インフルエンザで倒れてしまったりしてたので、今年はなんとか体力を付ける方向で頑張りたいと思います。まずは週一でウォーキングをするくらいからかなぁ。
繰り返しになりますが、今年も無印吉澤と吉澤をよろしくお願いします。
[ツッコミを入れる]
2009/10/17
■[書評]2009年4月〜6月に読んだ本(みんなもマーケティング本を読むといいよ!)
元旦の日記で「今年は週一冊は本を読む」と宣言したのはさっぱり守れていないのですが、4〜6月に読んだ本についてメモしておきます。この時期はマーケティング関係の本を色々読んでました。
- ポジショニング戦略
- コトラーのマーケティング・コンセプト
- キャズム
- [新版]MBAマーケティング
- イノベーションのジレンマ
- クリティカルチェーン
- ビジュアライジング・データ
----
)](http://ecx.images-amazon.com/images/I/51WCIcQzNKL._SL160_.jpg "ポジショニング戦略[新版](アル・ライズ/ジャック・トラウト/フィリップ・コトラー(序文))") ポジショニング戦略[新版](アル・ライズ/ジャック・トラウト/フィリップ・コトラー(序文))
ポジショニング戦略[新版](アル・ライズ/ジャック・トラウト/フィリップ・コトラー(序文))
「ポジショニング」というマーケティング用語を生み出したアル・ライズ自身による、ポジショニングの解説書です。
本書によると、ポジショニングとは「消費者の頭の中にあるイメージを操作し、それを商品に結びつける」ことと定義されています。消費者は日々膨大な情報に翻弄されているため、頭の中の情報爆発を防ぐために製品のブランドやランク付け(すなわちポジショニング)が重要である、というのが著者の主張です。原著は30年以上前に発刊されたそうなのですが、この点は今でも有効な主張に思えます。
本書では、有効なポジションをつかむための方法や成功例が多数紹介されているのですが、個人的に特に印象深かった話をいくつかピックアップしてみます。
- 重要なのは、人の頭の中に一番に入っていくこと。(p.29)
- 新製品は、必ず既製品に対抗する形でポジショニングしなければならない。消費者の「頭の中のはしご(ある基準に基づくリスト)」を作り、その中で既製品より上に登らなければならない。(p.42)
- 成功したいなら、ライバルのポジションを無視してはいけない。もちろん、自分のポジションを無視するなど言語道断。(p.46)
- どんなポジションでも良い、自社がすでに消費者の中に確立したポジションを活用する。(p.52)
- パワーのある企業がよい商品を生むのではなく、パワーのある商品がよい企業を生み出す。例えば、コカ・コーラ社は、コカ・コーラという製品が持つ実力(製品力)の反映でしかない。(p.63)
- 自社製品ラインナップの抜け(工場の穴)を埋めるのは間違っている。消費者の頭の中でなく、工場の中で穴を探してしまうと、市場におけるポジションを見逃してしまう。その穴は、市場では既にほかの製品に埋められていないか?(p.76)
- 新商品には新名称が鉄則。新しい商品に既存ブランドの名前を付けるのは、情報社会では命取りになりかねない失策。(p.126)
Eric Sink on the Business of Softwareでこの本が強く薦められているのを見て、「マーケティング本か……」とやや尻込みしながら読んだのですが、マーケティング用語を全然知らなくても、読み物として十分面白く読める本でした。マーケティングに興味を持つための取りかかりの本としては、かなりお勧めできます。
----
") コトラーのマーケティング・コンセプト(フィリップ・コトラー/恩藏 直人)
コトラーのマーケティング・コンセプト(フィリップ・コトラー/恩藏 直人)
現代マーケティングの第一人者(らしい)フィリップ・コトラーによる、マーケティング用語の一言解説集です。読みやすく、それぞれの用語についての感じをつかむにはよい本でした。一方、マーケティング用語が順不同で(原著はアルファベット順に)解説されているため、マーケティング用語同士の関係や全体感をつかみたい方は、後述する「[新版]MBAマーケティング」の方がお勧めです。
ちなみに、本書によると「日本企業の90%はマーケティングを担当する専門セクションを置いていない」そうです(p.167)。コトラーはこれを、「マーケティング部門を置くと、そこしかマーケティングを考えなくなってしまう。日本では、全社員がマーケティングを意識して行動するのですばらしい!」みたいな観点で書いているのですが、それはたぶん違うよなあ……。個人的には、日本企業でもマーケティング部門をちゃんと用意して、そこに権限を与えた方が良いような気がします。
----
有名な「キャズム」の本です。一時期、ブログがブームになった頃に「キャズムを超えた」だの「アーリー・アダプタの影響力が云々」だの色々言われていたので、本書に出てくるキーワードだけは知っている人も多いと思います。僕も、今までそのへんのキーワードしか知らなかったので、改めて原著を読んで、「そういうことだったのか!」と驚かされるところが多かったです。
本書では、新製品がキャズムを超えるのが難しいのは、アーリーアダプタはその製品で何ができるのかを重視する(製品重視の視点)一方で、キャズムの先にいるアーリーマジョリティはその製品の市場を重視する(市場重視の視点)からだと主張しています。つまり、アーリーアダプタでの採用例がいくら増えても、市場を作れなければいつまでもキャズムを超えられない、と。この難題を解決するためには、ホールプロダクト(製品だけでなくその周辺のサービスなどを含む。今風に言うとエコシステムか?)の構築が重要であり、今後はホールプロダクトをR&Dの対象にしなければならないと論じています。
また、本書ではposition statementのひな形を以下のように定義していました。前回紹介したEric Sinkの定義よりはやや複雑ですが、これはこれで面白いと思うので紹介しておきます。
[ (1) 代替手段 ] で問題を抱えている
[ (2) ターゲット・カスタマー ] 向けの、
[ (3) ターゲット・カテゴリー ] の製品であり、
[ (4) この製品が解決できること ] することができる。
そして、 [ (5) 対抗製品 ] とは違って、
この製品には [ (6) ホールプロダクトの主だった機能 ] が備わっている。
----
") 改訂3版 グロービスMBAマーケティング(グロービス経営大学院)
改訂3版 グロービスMBAマーケティング(グロービス経営大学院)
※僕が読んだのは第2版なのですが、既に第3版がでているのでそちらにリンクしています。
マーケティングについての良い本を探しているときに、P2P todayの横田さんから「まずは一般的なフレームワークを一通り勉強したら?」とお勧めされた本です。マーケティング用語同士の関係や全体感が整理されており、確かに(僕のような)初心者が基礎知識をつけるにはとても良い本でした。さすがヨコタン。
一方、初心者向けではあるのですが、知識が網羅的に書かれているので、読んでも「マーケティングすげー!これは重要だよ!」みたいなテンションの上がり方はしないのが難点です。もし、マーケティングに興味があるなら、上に挙げたような別の本を先に読んでテンションを上げておいた方がいいかもしれません。
----
(クレイトン・クリステンセン/玉田 俊平太)") イノベーションのジレンマ―技術革新が巨大企業を滅ぼすとき (Harvard business school press)(クレイトン・クリステンセン/玉田 俊平太)
イノベーションのジレンマ―技術革新が巨大企業を滅ぼすとき (Harvard business school press)(クレイトン・クリステンセン/玉田 俊平太)
有名な「イノベーションのジレンマ」です。ちなみに初めて知りましたが、原題は "The Innovator's Dilemma" で「イノベーターのジレンマ」なんですね。
本書では、イノベーションのジレンマが起こる理由を、既存の製品を取り巻くバリュー・ネットワークという概念(これもエコシステムと同義か)で説明しています。企業がある製品を開発することが「技術的に」可能であったとしても、実績ある企業は自分たちが属するバリュー・ネットワークの財務構造や組織の文化に束縛されているために、そのバリュー・ネットワークを壊しかねない破壊的技術は採用できない、というのが本書の説明(の僕なりの解釈)です。
イノベーションのジレンマ自体はかなり有名な概念ですが、本書ではその中身をかなり深く掘り下げており、原著に当たる価値はあると思いました。特に、組織の能力はそのプロセスと価値基準にあり、組織の構成員がその両者を強く理解している(現在のバリュー・ネットワークで価値を生み出す能力が高い)ほど、「破壊的技術を導入させるためのインセンティブ」を組織の構成員に与えることは難しくなる、といったくだりは衝撃的でした。そういう意味で、本書の内容は組織論にも近いかもしれません。
----
") クリティカルチェーン―なぜ、プロジェクトは予定どおりに進まないのか?(エリヤフ ゴールドラット/三本木 亮)
クリティカルチェーン―なぜ、プロジェクトは予定どおりに進まないのか?(エリヤフ ゴールドラット/三本木 亮)
本書もビジネス書なのですが、こちらはマーケティングではなくてプロジェクトマネジメントに関する「ビジネス小説」です。ちなみに、ビジネス小説というのは、「ビジネス上の難題にぶち当たった主人公が」、「○○という新しい技術/手法/考え方を知り」、「仕事がうまくいくようになる」というテンプレートに沿った小説のことです。
冗長な部分を取り払うと、本書の主張はだいたい次のような感じです。小説スタイルで書かれているので、このまとめが正しいのかもあまり自信がないのですが……。
- 従来の経営は、部分最適が全体最適に繋がる、という経営哲学に基づいて行われていた。この経営哲学を本書では「コスト・ワールド」と呼ぶ。
- しかし、実際の現場では、部分的な改善が全体の改善には繋がらず、全体のスループットは強度の一番弱い部分に依存する。つまり、もっともスループットが出ない部分を補強する、という取り組みを繰り返す必要がある。この経営哲学を本書では「スループット・ワールド」と呼ぶ。
- 個々の作業ごとにバッファを用意するやり方は、コスト・ワールドに沿った考え方。スループット・ワールドに沿ったやり方としては、個々の作業見積もりはかなりタイト(作業の終わる確率が50%〜90%のスケジュール)に設定しておいて、作業の合流地点に大きな共通バッファを持たせる。
- 特定のスペシャリストがクリティカルパスだけでなく複数の非クリティカルパスに関わるために、結果として作業が遅れることがある。スペシャリストを守るための人単位のバッファも必要。
「ザ・ゴール」みたいなビジネス小説が好きな人にとっては面白いと思いますし、単に小説として読めば面白いと思うのですが……僕は話の結論や整合性(どこまでが作り話なのか?)が気になってあまり集中できませんでした。
----
") ビジュアライジング・データ ―Processingによる情報視覚化手法(Ben Fry)
ビジュアライジング・データ ―Processingによる情報視覚化手法(Ben Fry)
最後はビジネス書から離れて、プログラミングに関する本です(癒される……)。
本書は、Processingというプログラミング環境を題材に、情報の視覚化(Information Visualization)のやり方を解説した本です。冒頭で、「データの理解において最も重要なポイントは、どういう問いに答えたいのかを知ることです」と訴え、答えに至るまでの過程を以下の7ステップに分解して示しています。
- データ収集(acquire)
- 解析(parse) … 構造の付加、カテゴリ分け
- フィルタリング(filter)
- マイニング(mine) … パターンを見つけたり、数学的処理をしたり
- 表現(represent) … 視覚化モデルの選択
- 精緻化(refine) … 基本表現の改善
- インタラクション(interact) … 操作、表示のカスタマイズの手段を提供
前半では、このように「情報の視覚化」の考え方を示した上で、後半はProcessingを使って上記の各プロセスをどう改善できるかを示しています。
かなり面白く勉強になる本なのですが、書籍の内容とは別に、ProcessingがJavaベースなのが個人的にはどうしてもなじめませんでした……。これ、もうちょっと軽量なスクリプト言語をベースにした方がもっととっつきやすかったような気がするんですよね(ProcessingはJavaの上に軽量な環境を作ろうとしてるんですが、いかんせんJavaベースなので限界が)。やりたいことと比較して、Javaだとちょっと書くことが多くて面倒すぎるような。でも、この本自体は、色々新しい観点を示してくれていい本ですよ。お勧めです。
----
7〜9月分に読んだ本についてはまたあとで……。
[ツッコミを入れる]
2009/10/13
■[programming][GAE]RDBからGoogle App Engineのデータストアに乗り換えるときのつまずきポイントとか実例とか
先週末は、某温泉街に籠もってGoogle App Engine(GAE)を色々いじって遊ぶという2泊3日の合宿に参加してました。合宿と言っても「GAE」以外に特にテーマも決まって無くて、みんな適当に好きなことをやってたんですが、僕はGAEの初心者なので、
「リレーショナルデータベースのために書かれたテーブル定義を、Google App Engineに置き換えようとしたらどれくらい大変なのか?」
をテーマに決めて、下の本を読みながらコードを書いたり消したりして遊んでました。
----
■ 先にまとめ
まだ勘違いも多そうですが、今回分かった「リレーショナルデータベースに慣れた人のつまずきポイント」を先にまとめておきます。
GAEのデータストアでは、複合主キーのある表を作れない。
- 例えばJDOだと、@PrimaryKeyを複数のインスタンス変数に付けるとコンパイル時に例外が出る。
- ちなみに、主キーのない表も作れない。こちらもコンパイル時に例外が出る。
一意なIDを割り当てるためのカウンター(オートインクリメント機能)が必要なら、自前で実装する必要がある。
- トランザクション処理を使うことで、このようなカウンターを実装できる。
- JDOインターフェイスでは、valueStrategyにIdGeneratorStrategy.INCREMENT(なんかそれっぽい)を選べるが、GAEでは使えないらしく実行時に例外が出る。
UNIQUE制約に相当する機能もない。恐らく、自前で実装することもできない?
- UNIQUE制約は、自前で定義することもできない、ような気がする……。
- GAEのトランザクション処理は参照したデータに対する排他処理のため、新しく追加する行の値に対する制約にはなり得ないのではないか。
多対多の関係を表現しにくい。
- リレーショナルデータベースに慣れていると、多対多の関係を表現するときは、関係を表す表を新たに追加したくなってしまうけど……。
- GAEでは複数の表をまたがるトランザクションは基本的に作れないので、途中で処理に失敗した場合の例外処理を書くのがすごく面倒。
- 当然、JOIN処理なんて無い。
- 多対多を実現する方法としては、一方の表に、もう一方のIDのリストを格納する列を用意すると楽。GAEでは、「リスト内のいずれかの値がAに一致する」といった検索クエリを「listItems == :A」のような形で記述できる。
JDOとJPAのどっちを使えばいいのか分からない。
- JPAを選んでもリレーショナルデータベース固有の機能は使えないので、JDOを使っておけば良いような気がする。でも、情報がなくてよく分からない……。
以下は、上のつまずきポイントに気付くまでに、実際に書いたり消したりしていたソースコードの話です。文章の最後にソースコードも置いておきましたので、興味のある方はダウンロードしてみてください。
----
■ 具体例
最近作ったAndroidアプリ(Where's My Info?)のテーブル定義がシンプルだったので、これをGAEのデータストアに置き換えることを試みました。GAEのデータストアへのアクセス方法は以下の3種類があるのですが、今回は最も情報が多いJDOを使っています。
- JDOインターフェイス(Java Data Objects、汎用的な仕様)
- JPAインターフェイス(Java Persistence API、RDB向け)
- ローレベルAPI(Key-Valueで値を保持するAPI、高速だが低機能)
まず、元にしたAndroidアプリのテーブル定義は、以下のようなものです。個人情報(information)と情報提供先(knowers)の関係を、主キーのないinformation_knowersテーブルで表現しています。

これを、GAEのデータストアで定義すると、以下のようになります。GAE上で扱う表のことを、ここでは「エンティティ」と呼んでいます。

こうして見ると、リレーショナルデータベースでの定義と比べて、やや汚くなってるのが分かります。以下は、リレーショナルデータベース版との違いです。
- Knowerエンティティの列に、関係するInformationのIDのリストを追加。
IDを一意に割り当てるためのカウンタを追加。
- 主キーが必須なので、ダミーの主キーを定義している。
- 今この資料を書きながら思ったけど、IDを一意に割り当てるためのカウンタ類は、1つのエンティティにまとめてしまえそう……。
で、最後にこのアプリを、ユーザ毎に別の領域にデータを格納できるように拡張すると、データストアの定義は以下のようになります。

- 「110487681081245093660」というのは、Googleが提供するアカウント認証サービスから取得できる、ユーザ毎に一意なユーザID。
InformationエンティティとKnowerエンティティのキーには、ユーザID + "/" + ユーザ毎に一意なIDを使っている。
- ユーザIDとユーザ毎に一意なIDを組み合わせた複合主キーが使えたら、ホントはそっちの方がよかったんだけど……。
- クエリとインデックスの方法を使って前方一致検索をすることで、特定のユーザに関係する列のみを取り出すことができる。リンク先にあるのはPython版のコードだが、Java版でも同じ方法が使える。
実例とソースコードを、それぞれ以下の場所に置いておいたので、もし興味があったら覗いてみてください。
実例(注意:管理者=僕にはデータ丸見えなので、ホントの個人情報は書かないで!)
http://wheres-my-info.appspot.com/
ソースコード(上の実例で動いてるのと同じものです)
WheresMyInfoWeb.zip
----
■ 感想
Eclipseのプラグインを使ってると、Google App Engineのソースコードを書くのも、本番環境にデプロイするのもすごく簡単です。でも、このデータストアを使って大規模なコードを書くのは、正直言って全然出来そうな気がしません。
こんなのを使ってあんなgmailみたいな巨大アプリを書いてると思うと、やっぱりGoogleの連中はイッちゃってるよ、あいつら未来に生きてんな……と思っていたら、今回の合宿の参加者から「Googleの中では、BigTableに(GAEには含まれてない)Chubbyを組み合わせて使ってるんじゃない?」との指摘が。そんな、ひどい……。
[ツッコミを入れる]
2009/10/03
■[mobile][Android]自作Androidアプリ「Where's My Info?」をAndroid Marketに登録してみました
最近日記を書いていなかったので、すっかり書くタイミングを逸してしまっていたのですが、実はDoCoMoのAndroidケータイ「HT-03A」を持ってます。ビックカメラで実機を触って気に入って、HT-03A発売日(7月10日)の1週間後くらいに購入しました。
その後、Hello Worldレベルよりもましな「ちゃんとした体裁の整ったAndroidアプリ」を開発する作法を勉強しようと思って、暇を見ては(日記も書かずに)ちょこちょことプログラミングをしていたわけですが……今日ようやっとAndroid Marketに登録するところまでこぎ着けました。今日はここまでの経緯をネタにいろいろ書いてみようと思います。
----
■ 今回自作したアプリ「Where's My Info?」
最近、引っ越しをしたり、携帯電話を買い換えたりすることが多かったので、色々と不便を感じていました。具体的には、こんなあたりが不満でした。
- 何かの書類に申し込みするときに、メモなどを見ないと、新しい住所/電話番号を正確に思い出せない。
- 古い住所/電話番号をどこに提供したのかわからない。何かの申し込みのときに、古い住所/電話番号を使ってなかったか?
そこで、今回はこの問題を解決するために「Where's My Info?」というアプリを開発しました。あまり「Androidならでは!」という感じはしないアプリですし、既存のパスワード管理ソフトに似た面もありますが、携帯に載ってるとそこそこ便利なアプリなんじゃないかと思ってます。
以下は、Android Marketに載せるために作ったスクリーンショットと紹介文です。スクリーンショットは一部英語になってますが、日本語ロケールならちゃんと日本語が表示されます。
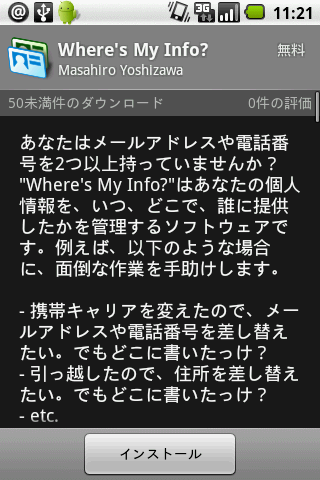
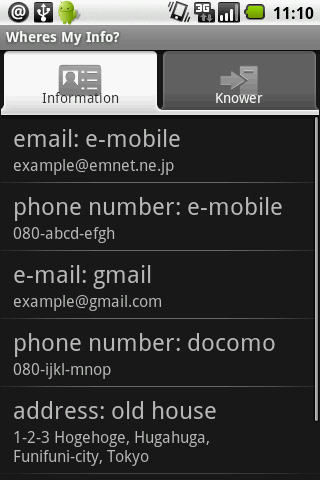
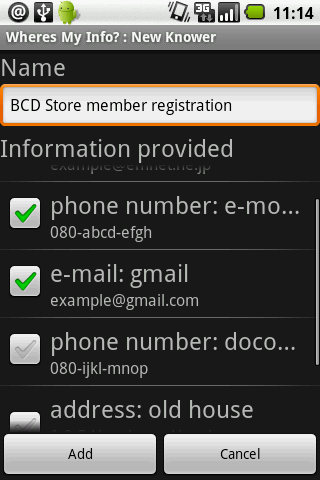
あなたはメールアドレスや電話番号を2つ以上持っていませんか? "Where's My Info?"はあなたの個人情報を、いつ、どこで、誰に提供したかを管理するソフトウェアです。例えば、以下のような場合に、面倒な作業を手助けします。
- 携帯キャリアを変えたので、メールアドレスや電話番号を差し替えたい。でもどこに書いたっけ?
- 引っ越したので、住所を差し替えたい。でもどこに書いたっけ?
- etc.
自分で使うために作ったアプリということもあって、今後もちゃんとメンテするつもりですので、是非使ってみて感想を聞かせてください。現時点では、これから以下の機能を追加しようと考えています。
- データのimport/export
- 情報提供先へのカメラ画像の追加(どこで情報提供したかわかりやすくする)
- 個人情報の並び替え
----
■ Androidアプリ開発の感想
基本的には、まあ、ものすごく敷居が低いですねー。
開発に使う言語はJavaで、かつEclipseでAndroidアプリを開発するためのプラグインもあります。エミュレータの起動や、実機へのインストールもそのプラグイン経由で出来るので、Java+Eclipseに慣れてる人なら特に楽だと思います。
ただ、これはフレームワーク全般に言えることですが、ライブラリが基本提供する機能から外れて、ちょっと気の利いたことをやろうとするととたんに詰まります。今回僕がつまずいたのは以下のポイント。
リストを表示するためのListViewをカスタマイズして、各項目の中にテキスト2行を表示したい。
ListViewからコンテキストメニューを呼び出したい。
- Long click on list activity item - Android Developers や How do you implement context menu in a ListActivity on Android? - Stack Overflow を見てもよく分からず、結局試行錯誤してるうちになんかうまくいった。
タブを表示させる方法がよく分からない。
- Add a "footer" in a TabActivity - Android Developers を参考にレイアウトのXMLを手直ししたらうまくいった。
ListViewの中にチェックボックスを作ったときに、そのチェックボックスの値を取る方法が分からない。
- Checkbox Text List :: Extension of Iconified Text tutorial :: anddev.org - Android Development Community を参考に手直ししてうまくいった。
戻るボタンを押すと古い情報が表示されてしまう……。
- Activityの後始末し忘れ。もう使わないActivityはfinish()でちゃんと終わらせる。
ダイアログのタイトルを消したい。
で、こうやって見て分かるように、細かいことを気にし出すと日本語圏にはあんまり情報がなくなってきます……。
----
■ 特に参考になった書籍、Webサイト
とはいえ、日本語でもAndroid関係の情報はかなり出てきていて、特に以下の本は役立ちました。幅広い話題についてかなり細かく書かれているので、この本だけ買っておけば大体なんとかなります。
") Google Androidプログラミング入門(江川 崇/竹端 進/山田 暁通/麻野 耕一/山岡 敏夫/藤井 大助/藤田 泰介/佐野 徹郎)
Google Androidプログラミング入門(江川 崇/竹端 進/山田 暁通/麻野 耕一/山岡 敏夫/藤井 大助/藤田 泰介/佐野 徹郎)
あと、WebサイトではTaosoftwareのblogにかなりお世話になりました。Android関係で疑問に思ったことを検索すると、日本語圏だと大体ここにたどり着くような感覚です。
Taosoftware
http://www.taosoftware.co.jp/blog/
とりあえず、今日はここまでで。Androidについては、またネタが溜まったらなんか書きます。
[ツッコミを入れる]
2009/08/08
■[tDiary]tDiary 2.1系から2.2.2にアップグレード
今回のリリースは、主にAmazonプラグインのためです。AmazonがAPI利用に認証を求めるようになったため、2009年8月15日以降、未対応プラグインでは利用できなくなります。amazon.rbを利用している場合は必ずアップデートしてください。
今回のバージョンアップ、Amazonプラグインを使っている人は対応必須みたいです。今まではセキュリティ対策のアップグレードがあっても、手でコードいじって済ませてたんですが、せっかくの良い機会なので今回はちゃんとコード入れ替えました。
なんか挙動がおかしい、というところがあったらtwitterあたりで教えてください。最近、日記を書く気が起こらなくてすっかりtwitterに引き篭もり中です……。
[ツッコミを入れる]
スパム対策のため、60日以上前の日記へのコメント及びトラックバックは管理者が確認後に表示します。
また、この日記に無関係と判断したコメント及びトラックバックは削除する可能性があります。ご了承ください。
また、この日記に無関係と判断したコメント及びトラックバックは削除する可能性があります。ご了承ください。

