 muziyoshiz.jpまでどうぞ。
muziyoshiz.jpまでどうぞ。
2006/10/02 第2回DHT勉強会議事録
■[P2P勉強会]第2回DHT勉強会の情報
- 日時:2006年9月18日(月・祝) 10:00〜17:00
- 会場:金沢工業大学大学院 東京虎ノ門キャンパス
- 参加者:80名弱(講演者含む)
- 各講演者の持ち時間は、質疑応答を含めて40〜50分
(首藤氏の講演はDHTのチュートリアルを兼ねていたため、講演60分、質疑応答20分) - プログラムはこちら(第2回DHT勉強会講演概要&タイムスケジュール)
- 司会はP2P today ダブルスラッシュの横田真俊氏
- プレゼン資料の一部は、各種資料置き場(Tomo's HomePage)にて公開中
過去のP2P勉強会と同様に、議事録を作成してみました。今回の勉強会は、ほぼ全ての講演がDHTの知識を前提としたものであり、非常に難易度が高かったです。それだけに、この議事録は勉強会に参加された方にとっても面白いものになっていると思います。
以下の議事録は、上記サイトで公開されているプレゼン資料に記載されていない部分、あるいは講演の中で強調された部分を主に記録したものです。勉強会に参加された方は当日の復習に、そして不幸にも参加できなかった方はプレゼン資料と併せてご活用ください。
なお、この議事録をお読みになる際は以下の点にご注意ください。
- 講演の内容は、編者の判断で一部検閲、修正しています
- この議事録はあくまで編者の個人的なメモとして公開するもので、編者の勝手な解釈が入っている可能性があります
- 編者による追記は脚注として示しました
- 質疑応答のQは質問、Aはそれに対する回答、そしてCはコメントです。一部の質問を除いて、質問者の名前は伏せてあります
加筆・修正などの提案がありましたら、コメント欄または個別にメールでご連絡お願いいたします。
■ 目次
- 開会の挨拶(Tomo's Hotline 西谷氏)
- オーバレイ構築ツールキット Overlay Weaver(ウタゴエ(株)取締役CTO 首藤氏)
- 世界規模情報共有プラットフォームの実現に向けて(日本電気(株) 加藤氏)
- P2PエージェントプラットフォームPIAXの理念と実装((株)BBR取締役CTO 吉田氏)
- AsagumoWeb Web over P2Pシステムの設計と実装(筑波大 池嶋氏)
- Chordプロトコルを活用したシステム開発の実際(大阪市立大 藤田氏)
- DHTにおけるセキュリティ対策(Tomo's Hotline 西谷氏)
- 閉会の挨拶(Tomo's Hotline 西谷氏)
- 謝辞
- 更新履歴
■ 開会の挨拶(Tomo's Hotline 西谷智広氏)
DHT勉強会開催の目的
- DHTという将来性のある技術に関して集中的にディスカッションする場を作る
- 長期的には、この勉強会をきっかけとしてボトムアップ的にP2P、DHT技術を啓蒙したい
■[P2P]オーバレイ構築ツールキット Overlay Weaver(ウタゴエ(株)取締役CTO 首藤一幸氏)
▼ 参考資料
講演資料(今回の講演資料そのものではなく、その元になった資料)
- Unstructured overlay と Structured overlay (Jan 13, 2006)
- オーバレイ構築ツールキット Overlay Weaver (SACSIS 2006, May 23, 2006)
関連サイト
参考文献
- Frank Dabek, Ben Zhao, Peter Druschel, and Ion Stoica. Towards a common API for structured peer-to-peer overlays. In IPTPS '03, Berkeley, CA, February 2003. (CiteSeer)
▼ 講演内容
DHTについて予備知識がない人のために、講演の前半は構造化オーバレイという側面からDHTを解説し、後半はOverlay Weaverを解説する。
□ 前半:DHTの解説
オーバレイ(Overlay)
- ファイルの検索、マルチキャストのトポロジの構築など、集中的にやれば簡単にできることを非集中的(decentralized)に実現するために、アプリケーションレイヤでネットワークを構築する
- 下位ネットワークとは違ったトポロジを持つこのようなネットアークを、オーバレイネットワーク、またはネットワークオーバレイと呼ぶ
- オーバレイという単語はコンピュータ関係で良く使われるので、単にオーバレイと呼ぶだけでは、文脈によって(オーバレイネットワークとは)違う意味に取られることがある
P2Pとオーバレイの関係
- Pure P2Pは非集中で何かやるから、必ずオーバレイが必要
- Hybrid P2Pでも、オーバレイを構築することがあり得る。例えば、アプリケーション層マルチキャスト(Application Level MulticastまたはApplication Layer Multicast、ALM)の場合はオーバレイを構築する
Pure P2Pで構築されるオーバレイ
- 非構造化オーバレイ(unstructured overlay)、構造化オーバレイ(structured overlay)のどちらかに分類できる
- この場合のstructuredとは、ノード(ピア)間のお隣さん関係に数学的な構造があること
- 今回の勉強会のタイトルにある「DHT」とは、このstructured overlayの一応用。「DHT」は、当初一つの研究分野として生まれてきたが、4年ほど前にこういう大枠での整理が成された
UnstructuredとStructured
- 一般論として、unstructuredは効率が良くない代わりに自由な検索が可能。structuredは柔軟な検索が苦手と言われている(研究レベルでは、structuredでも柔軟な検索を実現できる、と主張しているものもある)
- Structuredオーバレイのファイル共有ソフトへの応用は既に始まっている。eDonkey2kやeMuleのKadネットワーク(KadはKademliaの略)、BitTorrent、Azureusなど
Structuredオーバレイの基本
- ノードが受け持つID空間の範囲は、アルゴリズムによって異なる
- ID空間は、リングのものが多い(Skip Graphなどは例外)
- 肝はルーティング:資源にかかる負荷がノード数nに対してO(log n)。非常に大きいノード数をサポートできる
- 様々なアルゴリズムが提案されている(西谷氏がサイトで紹介しているCANやChord、小島氏が第1回DHTオフ会で解説したSymphony)
- ルーティングという整理の仕方をすると、DHTは、structured overlayの一応用と位置づけられる
Structuredオーバレイの基本(続き)
- DHTは、ルーティングの仕組みの上で、put(key, value)、get(key)を実現する。複数のピアでハッシュ表を作るからDistributed Hashtable
ルーティングの仕組みを使って、DHT以外のこともできる
- CAST(group anycast and multicast):マルチキャスト、エニーキャスト
- DOLR(decentralized object location and routing):メッセージ配信(インスタントメッセンジャーなど)
DHTの応用
- ただのハッシュ表なので、応用範囲が広い。もろもろの名前解決や位置解決に使える
- DHTでDNSを作ってみた研究も、物凄くよく知られているものだけで片手の数くらいはある。論文も多い
Structuredオーバレイ上のアプリケーションレベルマルチキャスト(ALM)
- チャネルをIDの数値で表現する(例えば、「テレビ東京」のハッシュ値をIDに)
- チャネルのIDをターゲットとして、各ノードからルーティングを行う。このルーティング結果を重ね合わせるとマルチキャストの配送木になる
- Scribeがこのやり方でマルチキャスト(実用ソフトではなく、論文上のアイディア)
- メリット:配送木の管理を、完全に非集中的に行える。チャネル数が物凄く増えた時に嬉しい
- デメリット:バカ正直に配送木を作ると、下位ネットワークの性質(非対称なADSLとか、NATとか)と噛み合わない
オーバレイへの参加・経路表の保守
- アルゴリズム毎に異なったやり方。ルーティングのオマケに見えるが、実装を始めるとそれよりも複雑で面倒
経路表のメンテナンスのやり方
- ノードが能動的に保守:Chord、Pastry、Tapestry
- 普段の通信を通して保守:Kademlia
- Kademliaは、経路表を保守するための特殊な通信が不要で、非常にシンプル。このシンプルさがエンジニアに好まれているためか、ファイル共有ソフトなどで応用されているDHTアルゴリズムはKademliaくらい
□ 後半:Overlay Weaverの解説
Overlay Weaver
- 最初は研究プロジェクト
- 2006年1月に公開
- 産総研での仕事の成果なので大部分の著作権は産総研が持っている。しかし、Apacheライセンスで公開しているため、改善部分は公開しなくても良いし、ビジネス利用も自由。非常に使いやすくなっている
- DHTアルゴリズム関係の名前には、糸を織るというアナロジーが多い(例:Chord(弦)、Tapestry(タピストリー、織物))。これらを織るためのツールということでOverlay Weaverと名付けた
- 記述言語はJava(マルチキャスト機能の一部はC)
- コメント、空行などを含めると3万数千行
Overlay Weaverの特徴
- アプリケーション層マルチキャストも実装している。DHTライブラリというより、Structuredオーバレイライブラリ
- Overlay WeaverはStructuredオーバレイという整理を採用し、その中でも更に整理したことで、様々なアルゴリズムを差し替えて使えるようになった。アルゴリズムを差し替えながら、アルゴリズム間のトレードオフを調整できる
- サンプルツールやエミュレータが充実している
- Message Visualizerを使うと、複数のピアが動いている様子をグラフィカルに楽しめる。アルゴリズム特有の通信パターンが目に見えるため、学習にも役立つ
XML-RPC経由でDHTを使うためのインターフェイスを備えている(Bamboo、OpenDHTと同じインターフェイス)。Bamboo、OpenDHT向けのアプリケーションをOverlay Weaverでも動作させることができる
- Bambooは実用だけを目指して作られているDHTのソフトウェア(Pastryベースのアルゴリズム)。OpenDHTという公開DHTサービスに使われている
(ここからデモ)
Overlay Weaverのデモ
- Message Visualizerを使ったデモ
- DHTのデモと、オーバレイマルチキャストのデモを紹介(アルゴリズムはChord)
デモの中で紹介された、Message Visualizerの小技
- 画面上でマウスのボタンを押したままドラッグすると、絵が回転する
- 回転の勢いを付けたままマウスのボタンを放すと、絵が回転し続ける
ID空間の表示方法が複数用意されている
- 表示方法を「直線」にすると、IDが増える方向のノードに対する通信は直線の上に、IDが減る方向の通信は直線の下に表示される。この機能を使うと、Chordの場合は通信が直線の上にしか出ない。つまり、ある種のアルゴリズム特性を可視化できる
- エミュレータ上のノードにtelnetで接続して、DHTシェルのコマンドを実行できる
- オーバレイマルチキャスト時には、グループ名のハッシュ値によってグラフ上の色も変わる
(ここからプレゼンに戻る)
ルーティング層の分解
- ルーティングドライバと、アルゴリズム記述部分が分離している
- アルゴリズム記述部分はたかだか数百ステップ(Chordなら500〜600ステップ)
- ルーティングドライバも差し替え可能 → iterative, recursive(時間の都合で詳しくは省略)*1
4000ノードのエミュレーション
- Pastry, Tapestryは数ホップで済む割合が非常に高い
- Chordだと10数ホップかかっている。Koordeだと更にかかる
実機200台での動作
- サンプリングレートが低かったので、シミュレーションよりもグラフがガタガタしてる
▼ 質疑応答
- Q)シミュレータのシナリオで、参加、離脱を扱うことはできる?
- A)出来る。ただ、シナリオの仕様を決めるときにポカをやっていて、一度ノードをコントロールすると、その後に新しいノードを起動できない(ノード起動→コントロール、の流れしか想定してない仕様になっている)。
しかし、ノードのサスペンドとリジュームの機能を使うことで、参加、離脱と同様のシミュレーションはできる。ただし、churn(ノードの出入り)の激しい実験はまだ行っていない。
- Q)ノードが安定しているかどうか、通信環境が良いかどうか、を考慮して経路を作るアルゴリズムはあるか?
- A)Overlay Weaverは扱っていない。世の中全般でも、Structuredではあまり思い浮かばない。
- Q)そのあたりを気にしなくても使えるのが(Structuredオーバレイの)良いところ?
- A)そうではなくて、やはり問題になる。「AとB、BとCは接続できる状況で、AとCが接続できない(実際に何パーセントかある)状況で、ホントにChordやPastryは動くの?」という論文も最近出てきた。
- Q)4,000ノードのエミュレーション実験をしたという話だったが、その数の根拠は? また、それ以上のスケーラビリティについてはどう考えているか?
- A)4,000という数字は、OSとマシンの制約によるもの。原因は2つあって、1つは、マシンのメモリが限界に近かったこと。また、Linuxカーネルはデフォルトの状態で32,000スレッドが限界で、実際はどうやっても16,000スレッドを越えられなかった。
アルゴリズムによって違うのだが、ノード毎に2〜4個のスレッドを立てるため、限界がここ(4,000ノード)に来ていた。
4,000ノードで良いのか、という問いについては完全な答えを持っていない。100と1,000、1,000と10,000ではどう違うのか、何個まで実験すればいいのか、という問いへの答えには常に悩んでいる。大規模分散システムに取り組んでいる人は、皆同じ悩みを抱えていると思う。
- Q)マルチキャストについて。ノード数が少ない時は(オーバレイネットワークは)スター型になると思うが、スター型からツリー型になるノード数の臨界点(閾値)について実験したか? また、論文等で何か分かっていることはあるか?
- A)そこは世界的にも未踏の地で、面白い研究テーマの一つである。例えば、修士の学生にとっては、なかなかいいテーマになると思う。(ホップ数のエミュレーション結果を見ながら)Pastry、Tapestryは2〜3ホップでルートに到着する。DHTとしては良いことなのだが、マルチキャストでは隣接ノードが多いハブが出来て、そこに通信が集中してしまうことが予想される。経路がどうなるかと、マルチキャストの配送木の構造は関係が深い(トレードオフが大きい)。
- Q)2つのノードの間に悪意あるノードを紛れ込ませることは可能か?
- A)自分では特に考慮していないので、(Overlay Weaverでは)弱い。悪意あるノード(malicious node)をどうするかというのは大きな問題で、"secure routing"というキーワードで検索すると論文が見つかると思う。ある観点で安全にしようと思うとCA(認証局)が必要になるとか、場当たり的な解しか無いのではないか。非常に難しい。
- Q)レプリカの問題について、例えばchurnが激しくなったときにネットワーク上にレプリカがどの程度残るか、といった評価を今後Overlay Weaverの上で行う予定はあるか?
- A)実用性向上は狙っている。レプリケーション(複製)の機能は9月の頭(version 0.4)に入れていて、指定した数(3つとか5つとか)のレプリカを作る機能は既にある。評価はしていない。
churnが激しい時にデータを維持する方法は、1)データを登録したノードが定期的にput、2)gracefulな(データを他のノードに引き継がせる)離脱をサポートする、の2つがある。
定期的なputはOverlay Weaverも行っていた(今でもオプションを変えると出来る)が、通信量が増えてしまう。また、putされたアイテム数に比例した負荷がかかってしまう。
これを避けるためには、オーバレイ上のノード数を見積もって、ノード数が多い時は頻度を下げる等の対策が必要。ただ、オーバレイ上のノード数を見積もる方法を、アルゴリズム独立に作ることができていない。例えば、Chordに限定すれば、successor listの密度を見ることでノード数を見積もれる。
一方、gracefulに抜けるのは、利点が少ない。結局、突然電源を切って抜けるような事態は想定しなければいけないので、gracefulな離脱は考えないくらいの方がいい。OpenDHTに使われているBambooも、gracefulな離脱は行っていないらしい。
実用まで考えると、完璧なやり方はなかなか無い。アプリケーション側で何らかの対策が必要だと思う。DHTのレイヤで自動再putする方法も、その頻度をうまく調整すればある程度リーズナブルなのでは。
- Q)Overlay WeaverのNAT越え対策は?
- A)NAT越えの方針として考えているのは2つ。1)NATを避ける。つまり、グローバルIPアドレスを自由に使えるノードだけでオーバレイを形成し、NAT内のノードはそこに接続するだけ。2)NATをなんとかする。
Overlay WeaverはUDP hole punchingを既に実装しているが、完全ではない。まともに越える方法は多少考察しているが、労力に見合わないと考えて、まだやっていない。
■[P2P]世界規模情報共有プラットフォームの実現に向けて(日本電気(株) 加藤大志氏)
▼ 参考資料
▼ 講演内容(第1部)
講演は3部形式。それぞれで質問を受け付ける。
自己紹介
- 2001〜2004年頃、JXTAに参加
- JXTAに参加したのは、Project JXTA Developer Contestに応募したところ1位になったのがきっかけ*2。コンテストでは、(DHTという言葉は当時無かったが今にしてみれば)One-hop DHTと呼ばれる類のものをJXTAで実装し、その上にファイル共有アプリケーションを作った
- その後、P2Pが本職になってしまったため、オープンソースに参加することは出来なくなってしまった
P2Pに感じる魅力
究極のユーザ主義
- 最初はFreenet的発想にインパクトを感じた
- ユーザの手で何か(例えば言論の自由)を作る
共用インフラ
- インフラを持たなくてもサービスの提供ができる
- ISPがP2Pトラフィックを遮断したとしても、その気になれば草の根無線LANで自分たちのネットワークを作れる
P2PWeb(TM) … 世界規模情報データベース
- 名前について、ウェブ上で一悶着あったみたい*3なので、経緯を説明
- 元々は、JXTAでP2P web browserというものを作っていた時に、世界情報規模データベースの一般名詞(a P2P web)として使っていた
- その後会社でプロジェクトを立ち上げるときに、そのP2P webという名前が流行ったので、間のスペースを取ってプロジェクト名にした
- プレスリリースをするときに、何か問題が起こらないように商標出願した(登録商標ではない。拒絶されている)
加藤氏の考えていたP2PWebと、NECで取り組んだP2PWeb
- 加藤のP2PWeb:大規模ネットワーク、管理者不在、ユーザ指向、情報共有プラットフォーム
- NECのP2PWeb:大規模ネットワーク、セキュリティ、コンテンツ配信
情報共有プラットフォーム
- ユーザのユーザによるユーザのためのシステム
- (あまり好きな表現ではないが)分かりやすく言うと「Web 2.0をP2Pで実現」のようなことを想定していた
- 超低コストシステム
- キラーアプリがいまいち無い。ブログ、動画共有などを考えていたが、その後Webの世界で実現されてしまった。P2Pでクロールの周期を早くするなど、P2Pならではの検索にはまだ余地が残っていると思う
情報共有プラットフォームのアイディアを実現するために必要な技術
- P2Pネットワーク、検索、API(ユーザがアプリを作るために必要)、セキュリティ、等
- セキュリティはかなり真面目に取り組んだ
- NAT越えは、研究ではなくエンジニアリングなので、あまり取り組んでいない
P2PWeb browserのスクリーンショットの紹介
- 4ペインのクライアント(ディレクトリ階層ペイン、検索ペイン、ファイルリストペイン、コンテンツ表示ペイン)
- ディレクトリ階層ペインには、各ユーザがローカルディレクトリに持っているディレクトリ階層を重ね合わせて表示する
- ファイル毎にリモート、ローカルの表示あり
- ファイルに評価(良い、普通、悪い)を付けられる。内部的には、評価されるファイルへのリンク情報と評価内容を持ったファイルを新たに用意する
- ディレクトリ情報はDHTで共有。DHTに参加するのはグローバルIPアドレスを持つノードのみ。ファイル転送はHTTPで行うので、NAT越え可能
- 検索は、exact matchなら出来る
掲示板機能もある(このときは動かなかった)
- メモをやり取りするときには、テキストファイルをいちいち編集するのではなく、掲示板機能を使う
- 掲示板のデータそのものはXMLだが、このXMLの中では、データの表示に使うXSLを指定する。このXSLの中に、日記の書き込み機能などの各種アプリケーションを記述できるようにした(ユーザが利用できるAPIの整備)
- マージ機能をサポートしているので、オフラインでも掲示板に書き込める
▼ 質疑応答(第1部)
- Q)異なる2人のユーザが、ディレクトリ名も含めて全く同じ名前のファイルを作った場合はどうするか?
- A)その場合、P2PWebでは同じファイル名のファイルが2つ並ぶ。ただし、コンテンツIDは変わるし、ファイルに付けた評価も変わるので、そのあたりで区別できると考えている。
また、クライアントはローカルの無視リストを持っているので、ここにコンテンツIDを指定すれば余計なファイルは見えなくなる(無視リストの共有もやりたかったが、そこまでは出来てない)。
- Q)1人のユーザがファイルを修正した場合、新旧のファイルをどう扱うのか?
- A)新しいファイルをアップロードすると、コンテンツIDの違う2個のファイル(新しいファイルと古いファイル)が見えるようになる。また、古いファイルを無視リストに入れることで、見かけ上は対処できる。
- Q)1つのファイルを何度も評価するなどして、意図的に評価を操作できるか? また、そういう操作をどう防止するか?
- A)ソフトウェア上は1人1回しか評価できないようになっている。ただ、プロトコル(仕様)上は1人で複数の評価を付けることはできる。対策としては、あるピアIDから来る評価は1つに集約する、オンラインのピアの評価のみを考慮する方法などが考えられる(ただし未実装)。
- Q)掲示板の追記・削除は誰かが管理しているのか、それとも誰でも修正できるのか?
- A)掲示板には管理者がいないので、誰でも修正できる。削除について、XSLの仕様上は削除フラグを立てるだけで掲示板そのものが消えることはない。ただ、ファイル共有ソフトなので、ファイルを削除してしまうことは可能。
この削除を防ぐためには、ファイルの更新履歴(コンテンツIDの変遷)をうまく管理して、電子署名する、という方法が考えられる。
また、これとは違う問題で、名前を偽った書き込みの問題が考えられる。1人が2つのハンドル名に成りすませないように電子署名を付けて検証する、という機能は既に考案して実装している。
▼ 講演内容(第2部)
P2PWebの独自DHT実装:GISP
- HTTPのようなプロトコルとして規定しようと考えていた
- ChordやKademliaも試したが、最終的にはDe BruijnグラフベースのDHTを実装した
- De Bruijnグラフを使うと、Constant-degree DHT(ルーティングテーブルのサイズを固定にしつつ、ホップ数はO(log n)になるDHT)が出来る。人によっては、これをNext Generation DHT(第2世代DHT)と呼んでいる
- DHTも一段落したので、レプリケーションの研究はホットになってきている
- P2Pネットワークを作る上で、DHTである必要はないと思っている。スケーラビリティ、非集中であれば良い
De Bruijn*4グラフ
- 一方向リンクの張り方に特徴がある。例えば、ID=xyzのノードからは、ID=0xyのノードとID=1xyのノードに対して一方向リンクを張る
- Right Shift Routing:一方向リンクを利用したルーティング。例えば、ID=xyzのノードからID=abcのノードにメッセージを送る時は、IDが xyz → cxy → bcx → abc のノードへ順にメッセージがルーティングされる(終点のIDと始点のIDを繋げたabcxyzを左に進むので、Right Shift)
- De Bruijnグラフをルーティングに利用した例が、KoordeやBrooseなどのDHTアルゴリズム
Broose:De Bruijnグラフ with Kademlia flavor
ノードIDが6ビットの例
- ノードIDの上位3ビットをDe Bruijn、下位3ビットをその下にぶら下がるBrother Lookupに使った場合のトポロジ
- Brooseという論文ではシミュレーションしか行っていないのだが、(加藤氏は)今回自分なりに実装してみた
実装上の工夫
- ホップスキップ:キャッシュを使って出来るだけショートカットする
- ネットワークサイズのオーダ推定(必要):上の例ではノードIDの上位3ビットをDe Bruijnに使っていたが、ここを何ビットにするかを全ノードがそれぞれ推定する
▼ 質疑応答(第2部)
- Q)128ビットや160ビットという実際の規模のDHTネットワークでは、Right Shift(De Bruijnルーティング)に使うビットが増える分だけホップ数が増えていくが、その対策は?
- A)ID空間が128ビット分でも、実際のノード数はそこまで無い。そこで、この方式ではRight Shift Lookupを何ビット分行うべきか推定する必要がある(必須)。IDがランダムに割り振られることを仮定した上で、自分のルーティングテーブルを見て、何ビットにするか推定する。これを全ノードが行う。
- Q)各ノードが独立に推定するのでは、偏りが出てしまうのでは?
- A)何ビットにするか推定するためには、ルーティングテーブル上のノード数の対数を調べればいい。従って、ノード数に1個や2個ズレがあっても、推定結果は狂わない。また、ビット数を多めに見積もって、安全側に倒している。加えて、ビット数が少し違うくらいであれば、ルーティング中に補正できるようにしている。現実問題として、それほど問題にならないと考えている。
- Q)推定を間違えて、小さいルーティングテーブルを作った場合にはどうなる?
- A)推定間違えへの対策は、上で述べた通り。ただ、意図的に推定を誤って、例えば一方は3で、もう一方は30という風にすると、ルーティングはうまくいかない。
▼ 講演内容(第3部)
DHT実装の評価
- エミュレーションで評価(シミュレーションではない)
- DHTのアルゴリズムではなくて、実装がどれくらい実用的に動くかを評価したかった
- デモで見せたアプリケーションを一番最初に作った時は、DHTを過信してデータを流したら、ネットワークがデータで溢れてしまった
→どれくらいデータを流して良いのか、定量的に知りたい - 評価する機能は、返り値がvoidのputと、返り値がlist of valueのget
既存シミュレータ
- p2psim:複数のアルゴリズムをC++で記述して、シミュレーションで評価できる
p2psimの問題
- 自分で新しく作ったアルゴリズムは評価できない (p2psim用に書き直す必要がある)
- 評価対象はlookupのみ
加藤氏の作ったエミュレータ
- 複数のノードが動作するサーバを複数束ねる
- DHTの実装は既存のものを使用
2通りのシナリオで評価
- staticシナリオ:churn無し。最初にデータをputした後は、ずっとgetし続ける
- join/leaveシナリオ:churnあり。何度か出入りしながらput→getを行う
実験
- 評価対象DHT実装はBamboo、Chord、FreePastry、BitTorrent、GISPv5、Overlay Weaver(アルゴリズムはChord)
- staticシナリオ:GISPv5は通信量は少ないが、成功率は他のDHT実装よりやや低い
- join/leaveシナリオ:GISPv5は、他のDHT実装より成功率がやや良い
独断ランキング
- 安定性 (成功率 > 90%)
1位: Bamboo、2位: GISPv5、3位: Chord - 応答性 (応答時間 < 5sec)
1位: Bamboo、2位: Chord、3位: GISPv5 - 軽量性 (通信量 < 1500byte/sec)
1位: GISPv5、2位: Chord、3位: BitTorrent - 使った感触で言うとBambooは非常に良くできてるが、通信量は多い。GISPv5は通信量の少なさを目的としていたので、その点は達成できていることが確認できた
- 安定性 (成功率 > 90%)
▼ 質疑応答(第3部)
- Q)第1部で述べていた、P2Pならではの検索について、具体的なアイディアがあれば。
- A)まだあまり取り組んでおらず、サーベイもできていない。DHTベースでN-gramをやってみよう、といったことなどは考えていたが、ブロードキャストベースのは今後考えてみたい。
■[P2P]P2PエージェントプラットフォームPIAXの理念と実装((株)BBR取締役CTO 吉田幹氏)
▼ 参考資料
講演資料
- P2PエージェントプラットフォームPIAXの理念と実装(PDFファイル)
(※2006/10/11追記:当日使用された講演資料とは若干記述の異なる部分があります)
- P2PエージェントプラットフォームPIAXの理念と実装(PDFファイル)
関連サイト
▼ 講演内容
前半はPIAX(ピアックス)の理念の話、後半は実装の話。
自己紹介
- BBRというベンチャーに属している
- 総務省のユビキタスプロジェクトの関係で、阪大の招聘研究員という立場にもいる
PIAXの理念(資料p.3〜4)
- オブジェクトの中から必要なものを発見し、発見したオブジェクトからサービスを構成するのがユビキタスネットワークの課題
- 将来ユビキタスネットワークが巨大になったときに備えて、共通プラットフォームを作る必要がある
ユビキタスP2Pサービス(資料p.6)
- Semantic Webの流れは、いずれはP2Pになる
- P2PはStructuredになって効率化が図られているが、今後は知識高度化の方向に行く
- 2つの流れが融合して、将来的にはUbiquitous P2P serviceが生まれる
P2PエージェントプラットフォームPIAX(資料p.7)
- PIAX(ピアックス)はP2P Interactive Agent eXtensionsの略
- モバイルエージェントの場合は、移動先が分からないとエージェントと通信できない。一方、P2Pエージェントは、P2Pネットワークを利用することで移動先が分からなくても通信できる。そのため、よい意味でいい加減な分散が出来るようになる
P2Pエージェントのモビリティ(資料p.8)
- 弱モビリティ(スタックを含むcontextの移動はしない)をサポート。Javaで実装すると、こちらの方が実装しやすい
- P2Pエージェントが移動することによるメリットは、主に4つ
- 帯域の効率的利用:これは、電話で話すか会議を持つかの違いに似ている。簡単な話なら電話で済むが、密に話そうと思うと相手先に出向いて話して帰ってくる
- P2Pアプリケーションの耐性:これが一番大事なところと考えている。P2Pネットワークは構成が変化するが、アプリとしてはその影響をなるべく受けたくない。これを防御するためにエージェントを複製させ、複製も同じエージェントとして見せる技術が必要になる
PIAXのアーキテクチャ(資料p.10〜11)
- 本日関係するのは、P2P overlayというレイヤ
- RPC / Streaming Wrapper:PIAXでは、グローバルIPアドレスを持っているリレーピアが、NATの中からの通信を中継することでNAT越えを実現
- P2P Overlay:複数のオーバレイをプラグイン化し、アプリケーションの用途毎に切り替えて使う
- Auth, Security Support:P2P基盤を作ると必ず安心・安全が問題になるので必要。PKIベースのピアおよびエージェントの認証等
マルチオーバレイ(資料p.12)
- 複数のオーバレイが必要な理由を表にした
- 範囲探索:僕らは地理的探索(2次元の範囲探索)をする必要があったのだが、DHTではこれが難しい。そこでSkip Graph、LL-Netを使っている
- 連想探索:ソーシャルネットワークのようなものをピアで形成したときに、「3ホップ先まで探す」などの検索を行う
- 意味探索:DHT+α(キーワードベクトルなど)が必要
- 完全一致+範囲探索のような複合的なクエリパターンは今後の課題
LL-Netの紹介ビデオの上映
- 本研究はモバイル端末もピアとして含めているので、移動してもリンクの再構成が少なくなるようにしている
- ピアに緯度経度が付いていることが前提条件(緯度経度がないと探索対象になれない)。GPSやアクセスポイント等で取得することを考えているが、ここではout of scope
現サポートのオーバレイネットワーク(2)(資料p.14)
- ヒューマンネットでの検索クエリの例:建築に詳しくて、信頼度が60%以上の人を検索
P2PエージェントAPI(資料p.15〜17)
- 発見型は、P2Pエージェント特有の機能。普通のメソッド呼び出しではpeerIdやagentIdが必要だが、発見型ではこれらが不要
PIAXの実装 - Skip Graphについて(資料p.18)
- 今日はDHT勉強会ということで、Skip Graphについてちゃんと説明したいと思って来た。是非、今日はこれを知ってもらいたい
- PIAXの場合は、StructuredオーバレイはSkip Graphしか実装していない(資料p.22の図を参照)
Skip Graph(資料p.19)
- Skip Graphの後、同様の内容で、SkipNetが発表されている。何故同内容の研究が違う名前で発表されているのかは謎。Skip Graphの方が論文としてオリジナリティがあるので、こちらを尊重している
- ピアには、IDとkeyが振られ、どちらをキーとした検索もlog Nで実現できる。一粒で二度おいしい
Skip Graphの基本構造(資料p.20)
- 図中のアルファベットはkey(ABCの順に並んでいる)
- アルファベットの上または下に付けられている2進数はID
- 一番下のリング(Root Ring)はアルファベット順に並んでいる
- レイヤが上がると、IDに従ってリングを分割する
- 全体的には、バランスした木構造になる(Skip Listの特徴)
レイヤー構成図(資料p.22〜23)
- 改良前はBase DHT(Kademliaを想定)の上にLL-Netを実装していたが、Base DHTとLL-Netの両方のルーティングテーブルをメンテしなければならず、非常に非効率だった
- 改良後はSkip Graphのルーティングテーブルに一本化された
参考:P2P技術(資料p.24)
- 私は、StructuredはDHT baseとnon DHT baseの2種類があると考えている
- non DHT baseの代表がSkip Listベース
アプリケーション事例(資料p.26〜28)
- ワンダーキャッチャー:PIAXもこのアプリケーションの土台として使ってもらって、いろいろ実装上の課題も発覚した
- MapWiki:Google Mapsを使った情報共有システム。PIAXの上に載せることで、性能向上した
まとめ(資料p.30)
- 早ければ10月中にもPIAXをオープンソースとして公開
- 共通プラットフォームとしてはセンサ等も扱う必要があるため、GCJ(GNU Compiler for Java)を使ってネイティブ化し、ARMデバイス(アルマジロ)にも組み込んだ
▼ 質疑応答
- Q)近接オブジェクトの発見にベイジアンを使う話があったが、どういうものを想定しているのか?
- A)ベイジアンには、ベイジアンネットやベイジアンフィルタなど、いろいろな使い方がある。
講演の中でソーシャルネットワークをサポートするunstructured overlayの話をしたが、このフィルタとしてベイジアンフィルタを使うと、より精度の高い口コミ情報が取得できる。また、センサで得られる色々な情報の関連性を知識として扱うと、その関連性を辿りながら情報を取得できる(コンテキストアウェアネス)。
- Q)ベイジアンのような統計処理をピアで行わせようとすると、何の統計をどう取るかに、制限がかかる。一括処理だと統計はしやすいが、ピアで行うのは難しい。そもそもデータが取れない。統計処理の結果をルーティングに使えないか色々考えてみたが、なかなか難しい。何か解はないか?
- A)プラットフォームを作るのが精一杯で、今はまだ部品を作っただけという段階。状況依存ベイジアンフィルタというエージェントを作ったが、評価はこれから。
- Q)Skip Graphについて。IDとkeyの両方を使って多目的に使えるのは分かったが、何故それで今までより多くのデータが扱えるようになるのか?
- A)Skip Graphを使うことで、DHTよりもスケーラビリティが上がるわけではない。O(log N)である点は、DHTと同じ。パフォーマンスを犠牲にしていないので、個人的には、Skip Graphは非常に良いoverlay structureであると思っている。
- Q)LL-Netと同様のことは、例えばCANのようなDHTでも出来ると思う。CANとLL-Netの違いは?
- A)CANはO(log N)で無い上に、プログラムが面倒(シンプルでない)。そのため、CANは最初から除外しており、あまり比較していない。
CANはn次元のレンジをやりやすいというメリットがある。しかし、n次元は、次元を落とすことで対応可能と思っている。
LL-Netは地理情報を扱うため2次元だが、それを(Skip Graphが扱えるよう)1次元に変換するためにヒルベルト関数を使っている(Z-orderingと呼ばれる)。これにより、2次元を1次元化して範囲検索に使っている。
下のレイヤの実装を出来るだけシンプルにしないと、現実的な問題(耐障害性、安定化)も難しくなる。
- Q)Skip GraphよりもDHTの方が優れている点はあるか?
- A)DHTとSkip Graphの両方を実装した感触から言うと、Skip Graphの方が優れていて、弱点が無い。嘘だと思う人は、Skip Graphの仕組みを勉強してみてほしい。
唯一、Skip Graphが弱いと思うところは、ルーティング先の選び方に柔軟性が無いこと(例えば、KademliaなどのDHTアルゴリズムは、ネットワークの近接性や稼働時間を考慮して、複数のノードからルーティング先を選べる)。しかし、Skip Graphはレイヤを上下して探索することが出来るので、それほど弱点にはなっていない。
■[P2P]AsagumoWeb Web over P2Pシステムの設計と実装(筑波大 池嶋俊氏)
▼ 参考資料
- 講演資料は配布なし
関連サイト
▼ 講演内容
DHTとハイパーテキストの組み合わせ
- DHTはいわゆるMap
- 部分一致や全文検索は苦手なので、ファイル共有ソフトには向いていない
- URLはWebページに対して一意なので、極論するとWWWはURIからページへのMapと考えられる
→ WebはDHTに向いているのではないか?
Webサーバの負荷分散
- あるページが注目されると、そのページがあるサーバにアクセスが集中して負荷がかかる
- 既存の解決手法:CDN(Contents Delivery Network)、プロクシを使ったキャッシュシステム、Webサーバのクラスタリング
→ アクセスが少ない時は、これらのサーバは無駄になる - このような遊休サーバの問題を解決するのにP2Pが使えると考えている
Webサーバ管理の負荷分散
サーバのレンタル費
- 通常、レンタル費は転送量の多さで決まる
- 例:はてなブックマークで一時的にアクセス増 → サーバレンタル費増額 → やむなくサイト閉鎖
コンテンツの管理責任
- 掲示板などを開設していると、他人の書き込みが原因で管理者が訴えられることもあり得る
- 例:掲示板サイトを開設していたら、動物病院に名誉毀損で訴えられる
- P2Pでこの問題を回避。ネットニューズ(NNTP)の作者が訴えられたという話は聞いたことがない
AsagumoWeb
- AsagumoWebは、P2P技術でWebサイトを作る(Web over P2P)
- 一方、P2P掲示板の新月は、Webサイトを運用する技術を使ってP2Pを実現(P2P over Web)
- AsagumoWebの目的は、負荷が1つのサーバに集中しないこと
- Freenetは一度公開したページを後から編集できないが、AsagumoWebでは編集もサポートしたい。また、ある程度動的なページも扱いたい
AsagumoWebのデータ構造
- 掲示板をページとして作る
- 書き込み、削除等の変更は、そのページにデータブロックを追加するという形で行う
- 削除機能は、「削除」というデータブロックをページに追加することで実現
- 各ページにはWindowsで生成できる一意なID(GUID)が割り振られる。ページ間でリンクを張る時は、このIDを使用する
アプリケーションの動作
- Webブラウザを使ってページにアクセスすると、そのページを表示するためのアプリケーションをローカルにダウンロードして実行
- アプリケーションはページと、そのページのデータブロックを全て収集し、HTMLに変換して、Webブラウザへ渡す
- ページへの書き込みも、このアプリケーションに渡す
- アプリケーションを勝手にダウンロードするのは危険なので、将来的にはセキュリティ機能を使いたい(今は、過去に一度も実行したことのないアプリケーションについては警告を出す)
P2P通信方式
- DHTを使っていない実装(NNTPモード)と、Kademliaを使った実装(Kademliaモード)の2種類を実装した
NNTPモード
- NNTPにとても近いプロトコル。ノード同士が一定時間毎に通信を行って、相手が持っていないデータがある場合はそれを配送する
- それなりに動くが、全てのノードが全てのデータを持っていなければならない
Kademliaモード
- C#で約1000行の実装。k-bucketの実装などが一部不十分
- Kademliaは実装が楽で、首藤さんのスライドだけで実装できた。ChordのStabilizationのような問題もない
高速化のためのズル
- DHTには、データを持っているノードのIPアドレスではなく、データ本体を保存
- 周りのノードにもデータを複製
まとめ
- 今後評価し、未実装の部分を実装し、公開するかもしれない(そこまで頑張れるか……)
- AsagumoWebのデモ
▼ 質疑応答
- Q)NNTPモードの同期のタイミングはどれくらい?
- A)去年、実際にインターネット上で10ノード動かしてテストしていた時には、1分に1回とか10分に1回というタイミングにしていた。何もない時は10分に1回だが、自分自身に新しい書き込みがあったときにはすぐに通信する。また、情報のプッシュも行う。
- Q)Kademliaモードでレプリカの話が出たが、データを持つノードがレプリカ先まで含めて全て落ちたらデータは消える?
- A)データをプッシュしたノードは数時間おきにデータを再プッシュするので、すぐに消えることはない。ただ、ファイル数に比例して負荷が増えるので、何か対策を考えなければいけない。
- Q)掲示板アプリケーションはどうやって記述している?
- A)アプリケーションは全てC#で書いている。各ページは、そのページを作成したアプリケーションを表すアプリケーションIDを持っている。このアプリケーションIDをキーとして、DHTからアプリケーションDLL(これも1つのブロック扱い)を取得できる。
現在は実装していないが、将来的には.NET Frameworkのコードアクセスセキュリティ機能を使いたい。しかし、コードアクセスセキュリティ機能を使うとMonoでは動かなくなってしまうので悩んでいる。
- Q)Google over AsagumoWeb、YouTube over AsagumoWebは作れるのか?
- A)出来ない気がする。ただ、GoogleがAsagumoWebをインストールして、AsagumoWeb上をクローリングしてくれれば、作れるかもしれない。例えば、WinnyをGoogle対応にしたかったら、GoogleがWinnyネットワーク上の全データをダウンロードしてくれればいい、というのと似た話。
- Q)そういう話ではなくて、Googleは物凄く大きなストレージや計算環境を持っているが、それをAsagumoWeb上で動かせるのか?
- A)それは多分無理。一方、YouTube over AsagumoWebについて考えると、まず今の実装で大きなファイルを扱うのは難しい。また、悪用される恐れがあるので、大きなファイルを扱えるようにするつもりもない。だから、例えばTorrentファイルをアップロード出来るようにするのがいいかもしれない。
- C)Googleを分散環境で実現できないかというと、アイディアとしては実現できるはず。Googleのドメインだけでなく、検索クエリを含むURL全体をDHTのキーとして考えれば、DHT上でもGoogleを実現できるのではないか。
- Q)データを削除するという動作はある?
- A)データに対して、「非表示にする」という命令を書き込むことはできるが、データそのものを削除することはできない。また、データを持っているノードが1つなら、そのノードにinvalidate要求を送れば削除できるかもしれないが、AsagumoWebでは、データを取得したマシン上にキャッシュが残るようにしているのでそれも無理。
- Q)何故、(書き込み操作をブロックという形で蓄積する)ログファイルシステムにしたのか?
- A)データをそのものを更新するためには、同期の問題を解決する必要があったから。
- Q)だとすると、複数のユーザが同時に編集した時の衝突制御はどうしている? 掲示板やWikiの場合は衝突が問題にならないが、矛盾が発生するようなWebアプリケーションのことを考えるとログファイルシステムは果たして適切なのか?
- A)(新月のような)既存のP2Pアプリケーションで実現している機能を重視したため、このような実装にした。
- Q)DHTを使った方のプロトコルでは、データは特定ノード及びその近隣ノードにのみ置かれるので、負荷分散にならないのでは?
- A)その指摘はごもっとも。ただ、並列で20個のノードに同時にクエリを投げて、最初に帰ってきた答えを採用するというDHTもある。
- C)その場合、何カ所にデータを分散するかは、プロトコルの実装者が予め決め打ちする形になる? だとすると、アクセス先のノードが空いているときには、並列に投げられたクエリは無駄になる。講演の最初に、事前にサーバ増強する必要があるという既存のWebの問題をP2Pで解決する、と言っていたが、結局同じ話になってしまうのではないか。
- Q)Webをブラウズするときに、URLを直接指定すればページを見れると言っても、普段はサーチエンジンを使う。AsagumoWebはWebに似たシステムだが、AsagumoWebにとって、Webのサーチエンジンに当たるものはAsagumoWeb上で動くのか? それとも外に作る必要があるのか?
- A)上の質問で答えたように、AsagumoWeb上にサーチエンジンは作れない。個人が趣味でやっているようなサイトを分散したい、というのが一番の目的。
- Q)つまり、AsagumoWebは既存のWebを補助するシステム?
- A)その通り。
■[P2P]Chordプロトコルを活用したシステム開発の実際(大阪市立大 藤田昭人氏)
▼ 参考資料
講演資料
- Chordプロトコルを活用したシステム開発の実際(PDFファイル)
▼ 講演内容
自己紹介と、修士課程の経過(資料p.2〜6)
- P2Pと関わるきっかけは、永続アーカイブ(Persistent Archive)
- 当初(修士の初め頃)は「OceanStoreを使えば永続アーカイブを実現できる」と楽観的に考えていた
- その後、OceanStoreとそのプロトタイプのPondを詳しく調べたところ、全然ダメダメ
- この時点で修士課程の期間の2/3が経過。しかし、Structured P2P が永続アーカイブの足場になることだけは確信できた
- 第三者に評価されていて、文献が多いと思われるChordにスイッチ
Chord(資料p.7〜10)
- "Chord: A Scalable Peer-to-peer Lookup Service for Internet Applications"というタイトルの論文が3つある。資料には、ページ数が少ない順に記載。Chordを実装するなら、3つ目の資料まで読む必要があると思う
- MIT PDOSというのは、200〜300人体制の巨大な研究組織。この中でChordの開発だけでなく、理論的な解析やシミュレーション、アプリケーション開発などが行われている。そのため、http://pdos.csail.mit.edu/pubs.htmlあたりを漁ると、ざくざく論文が出てくる
Chord - 実装とその問題点(資料p.11〜15)
- アプリケーションレイヤでファイルシステムを作るための開発キットである、Self-certifying file system (SFS)を使っている
Chordのインストールを試みて、さんざんはまる
- 加藤氏は最新版のChord実装を評価したということだが、どうやってインストールしたのか是非聞いてみたい
- (途中の資料は時間の都合でパス)
- 結論:Chord自体は素晴らしいと思うが、MITの実装は最悪。Chordのメーリングリストでは、未だにインストール方法を質問するメールが飛んでいる
Chord実装 - 取り合えず頑張ってみた(資料p.16〜18)
- 4.x系のFreeBSDでないとうまくいかなかった
- 最新バージョンのビルドには失敗
- CFSの開発はだいぶ前に止まっていたので、CFSがアップデートされていた頃のコードを1つずつしらみつぶしにチェックアウトしてコンパイル(3年分くらい試した)
- lvyのホームページにあった2003/02/20のソースコードを使ってビルドすると、なんとなくうまくいくことを発見
- しかし、CFS/lvyは、対象ファイルが1MB以上になるといきなり刺さる(クラッシュする)
- 結局、MIT PDOS実装は諦めた
- でも、取り合えず修士論文は終了して、今はD1。研究は継続しているので、早く代わりの実装を探したい
オルタナティブ(資料p.19〜22)
- リファレンス実装が欲しいので、既存実装をインストールすることにこだわっている
- Javaで実装されたOverlay Weaver、C++で実装されたMACEDON(MACE)
- Internet Indirection Infrastructure (i3)にも簡単なChord実装が含まれている
- 4月以降は、手軽なi3 Chordを使って作業している
i3 Chordの実装(資料p.23〜24)
- ちゃんと動いているのかよく分からない。おかしいおかしいと思いながら作業している
i3 ChordのLookup、Stabilization(資料p.25〜28)
- ソースコードを見てみたところ、i3 Chordはfinger tableの高速lookupをサポートしていない(!)。つまり、successor listしか無いのでルーティングはO(N)
- ただし、predecessorも3ホップ先くらいまで持っている
- i3 Chord独自のping/pongメッセージによるトラフィック量が多い
さて、困った…(資料p.29〜30)
現在、RDBMSをP2Pで共有する研究プロトタイプを作っている
- P2Pを活用した小規模データベースの集約化
情報処理学会研究報告2006-DSM-042
情報処理学会DSM研究会, Jul.20, 2006
http://dspace.info.gscc.osaka-cu.ac.jp/~fujita/RESEARCH/DSM042/paper.pdf
- P2Pを活用した小規模データベースの集約化
- DHTの上位に乗っかるデータベース制御部分は、既にC言語で書いてしまっている
今後の開発の方向性:DHT実装をどうする?
- 選択肢1:取り合えず動いているi3 Chordを使う
- 選択肢2:finger tableをサポートするChordを作る
- 選択肢3:Overlay Weaverを採用して、データベース制御部分をJavaで書き直す
- P2PのシステムはJavaでの実装事例が圧倒的に多いので、選択肢3は有力(例:Pastry、Tapestry)
- 元々、自身がカーネル屋なので、DHT自身をカーネルサービスに入れることを狙うならCで実装するのが良いのではと悩んでいる
構造化オーバーレイを使ったアプリケーションを書くためには(資料p.31〜32)
- これまでの設計で感じた感想
- 構造化オーバーレイは、広域分散システムに共通する一般的な課題を解決してくれるとは限らないので、使うには努力が必要
- 構造化オーバーレイが技術として定着するためには、プログラミングの方法論の確立と開発のための優れた道具が必要なのでは? そうならない限り、非構造化オーバーレイに成果をつまみ食いされて終わってしまうのではないか
構造化オーバーレイ=DHT?(資料p.33)
"Towards a Common API for Structured Peer-to-Peer Overlays"
- DHTは構造化オーバレイを活用するための抽象的な概念の一つでしかない、という考え方
- Tier 0がChordに、Tier 1がDHashに対応している
- 論文の著者にPastry、Tapestry、Chordの開発者が名を連ねている。この3つのDHTアルゴリズムを合わせて考えられたモデル
"OpenDHT: A Public DHT Service and Its Uses"
- DHTが構造化オーバレイの基本的な抽象概念で、その上に色々積み上げる、という考え方(に見える)
- Recursive Distributed Rendezvous(ReDiR)はシンプルなput/getの上に実装されている、クライアント側での付加的な処理の実行をサポートするためのライブラリである。こういう機構を用意することで、構造化オーバーレイ=DHTの構図を崩さず、DHTでは不足してしまう機能を補う方策をOpenDHTは提案している
▼ 質疑応答
- C)(加藤)Chordのスナップショットを過去に仕事で動かしたことがあり、普通に動いた。私が直接動かしたわけではないが、すごく苦労したという話は聞いてない。ただ、昔のバージョンではだいぶ苦労したと聞いているので……間が悪かっただけかもしれない。新しいバージョンになるごとに、アルゴリズム的にも良くなっている。
ちなみに、(発言者は)DHashまでしか試しておらず、CFSは試していない。
- C)どのライブラリを使えばいいかという話は、C言語をベースにするならChordを使えばいいのではないかと思う。ただ、Overlay WeaverなどはXML-RPC経由で利用できるので、この機能を使えば今までC言語で実装した部分をJavaで書き直す必要はない。
- Q)講演の冒頭で「永続アーカイブをOceanStoreで出来ると思った」と述べていたが、そう思った理由は?
- A)OceanStoreの論文に「OceanStoreは科学データ用の非常に大きなデジタル・ライブラリやリポジトリを作成するために使用することができます。」と書かれているのを丸々信じたというのが正直なところ(参考:資料4ページ目)。
ただ、実際問題として、数百年オーダの長期保存となると、途中でアーキテクチャ(?)も変わるだろうし、それを維持していく人も変わるだろう。政府系の図書館では、その負担が問題になって、デジタルコンテンツの収集を積極的に始めるところまで踏み込めない。この問題を解決する手助けが出来れば、Internet Archiveのようなものを、もっとパブリックな形で始められるようになるのではないかと考えていた。
このように公共性が高いサービスであれば、一般ユーザの協力(ストレージ領域の貸し出し)も期待できるであろうし、SETI@homeのようなスキームを整備することはできると今でも考えている。
- Q)分散したデータベースをP2Pでまとめるという論文を執筆中であると紹介していたが、それはどういった問題を解決しようとしているのか?
- A)分散アーカイブの一種として、P2Pを使って文献(論文)のメタデータを配信することを考えている。メタデータの受信側でのローカルな検索を容易にするために、文献のメタデータを検索すると、リレーショナルデータベースのテーブル全体または一部がそのまま検索結果として返される、という仕組みを考えている。例えば、検索条件としてある著者が指定された場合は、検索結果として、テーブル内のその著者に関連するレコードが全て配信される。論文が完成したあとで、また詳しく説明したい。
- Q)OceanStoreの実装の問題点は?
- A)OceanStore自体はシミュレーションしか行われていないし、上のレイヤも、どこまで実装できているのか分からないJavaのソースコードが存在するだけ。
この研究グループは、その後OpenDHTの研究に移り、商業サービスとして提供できるDHTを目指している。現実的に使えそうな大規模ストレージの実装としては、OpenDHTの方が参考になるだろう。
- C)(吉田)Structured overlayイコールDHTかどうか、という議論を積み重ねていくのは良いことだと思う。
私は、DHTはstructured overlayの一つであると考えている。私が今回紹介したSkip Graphのように、他にも有効なデータ構造はあるに違いない。今後そういうものが色々生まれてくるときに、DHTを前提に考えていると、思考を狭めてしまうのではないだろうか。
講演の中では、DHTをベースに上に載せていくというアプローチを紹介していたが、これは狭い土台の上に大きな物を載せようとしているように見えてならない。そのため、今回あえてDHT勉強会でSkip Graphを紹介してみた。
(ここで、藤田氏が「首藤さんどう思います?」と話題を振った)
- C)(首藤)"Towards a Common API for Structured Peer-to-Peer Overlays"という2003年の論文のモデルをすごいと思って、Overlay Weaverの実装方針をああいう形(ルーティング機能の上に、サービスとしてのDHTやマルチキャストが載る)にした。
しかし、色々やってみて分かったのだが、その整理は完全ではない。そのモデルに合わないDHTアルゴリズムも存在し、例えばOverlay WeaverのKademliaの実装では汚いことをやっている。
どうすべきというアイディアは今のところ無いが、発想を狭めないようにstructured overlayとして考えるというのは良い観点だと感じる。
■[P2P][セキュリティ]DHTにおけるセキュリティ対策(Tomo's Hotline 西谷智広氏)
▼ 参考資料
講演資料
- DHTにおけるセキュリティ対策(PowerPointファイル)
参考文献
- Emil Sit and Robert Morris. Security Considerations for Peer-to-Peer Distributed Hash Tables. In IPTPS '02, Cambridge, MA, March 2002. (CiteSeer)
(※講演者による補足:ノードIDの生成方法とルーティングテーブルの正当性検証については、上記の論文をご参考ください)
- Emil Sit and Robert Morris. Security Considerations for Peer-to-Peer Distributed Hash Tables. In IPTPS '02, Cambridge, MA, March 2002. (CiteSeer)
▼ 講演内容
自己紹介(資料p.2〜3)
- 第1次P2Pブームが盛り下がっていた2004年に、横田さんと相談してP2P勉強会を企画
- 最近、 UNIX magazine 2006年10月号にDHT解説記事を寄稿
DHTのセキュリティとは?(資料p.4)
- 最近日本でも、DHTのセキュリティに関する研究が出始めている(首藤氏の再帰検索に関する論文)。今回の講演では、今後の発展性についてプレゼン
- 個人的には、DHTのシステム全体でのCIAや、さらに高度な機能(レプリケーション等)を包括した研究が必要と考えている
ルーティングの正当性検証(資料p.5)
- アイディアベースで検証が甘いのだが、議論の端緒として
ノードIDの偽装対策(資料p.6〜12)
ノードIDの生成方法
- 案1:ノードのネットワークアドレスをハッシュして生成する従来の方法
- 案2:ノードに払い出された電子証明書の内容をハッシュして生成する方法(西谷案)
- 案1は、NAT越えの問題がネック。ノードは必ずしもグローバルIPアドレスを取得できない
- 案2は、ノードに電子証明書を配布しなければならない点がデメリット。しかし、P2Pネットワーク上で認証を行う場合は、結局電子証明書を配布することになると考えている
案2では、電子証明書のリポジトリをどこにするかが課題
- 講演者は、ノードIDがHash(X+Y)のノードに証明書を格納する方法(案Q)を提案(Xは証明書のデータ、Yは定数)
情報管理範囲の正当性(資料p.13〜16)
- p.14の赤いノードのように、管理範囲を偽った悪意のノードをどうやって検証するか?
二次の隣接ノードに対して、情報管理範囲を確認する方法
- 一次の隣接ノードと二次の隣接ノード、どちらが悪意あるノードか判断できない。もっと有効な方法は? より多くのノードに質問する方法も?
- stabilizationが終了していないときは管理範囲に矛盾が生じるが、その悪意の有無をどう判断するか。矛盾の生じている期間の長さで判断?
ルーティングテーブルの正当性(資料p.17〜18)
- やり方次第ではある程度可能、という論文がある
局所的なノード数から全ノード数を推定できれば、その全ノード数からルーティングテーブルの正当性をある程度検証できる?
- 講演者が考えているノード数推定方法は3つ(資料p.18)
データの紛失対策(資料p.19)
- 紛失対策(レプリケーション)とDHTノードの負荷はトレードオフの関係にあるので、アプリケーションが扱うデータのサイズ等を考慮して、対策を決める必要がある
データの改ざん対策(資料p.20)
- 電子証明書を配布して、PKIを使えば検証は可能(防止はできない)
ノード間の認証(資料p.21)
- 電子証明書+チャレンジレスポンスでの認証を拡張すると、P2PでSNSを簡単に構築することができる(参考:Mixi Talking night〜SNSを考える〜)
- 最近、DHTを使ってワンタイムレスポンスをやっている人もいると聞いたことがある(私は詳しくは知らない)
多数の悪意ノード注入による攻撃(資料p.23〜30)
- 問題:どの程度の悪意のノードがあればDHTシステム全体としての機能がダウンするだろうか?
- 物性物理学で用いられるパーコレーション(浸透)理論を応用することで、この問題をうまく解決できるのではないかと考えている
- 資料p.25〜26の図は、赤丸が悪意あるノード。赤丸のノードを辿らずに端から端まで線を引けるか調べるのが、サイトパーコレーション。線を引ければ浸透する(この場合はノードを辿ってどこまでも行ける=ネットワークが機能している)と言える
- 複雑ネットワーク関係ではパーコレーションの研究が進んでいるので、そちらの成果を元にして、この問題を解決できるかもしれない
- 複雑ネットワークに関しては、複雑ネットワークの科学という書籍を参照
終わりに(資料p.32)
- DHTセキュリティ研究の分野は、まだそれほど積極的でないと考えている。ここにチャレンジすると非常に注目される可能性が高いのではないか
▼ 質疑応答
- C)ノードIDの生成にIPアドレスを使うか電子証明書を使うかという話があったが、私も電子証明書の方が良いと考えている。
例えばテラバイト級のストレージを扱っている環境では、IPアドレスの付け替えが起こると、データの大規模なマイグレーション(移行)が発生してしまう。電子証明書にも有効期限切れという問題はあるが、それでもIPアドレスを使うよりは良いと考えている。 - A)ChordがIPアドレスをハッシュとして使っているのは、NAT越えや商用ベースのことを全く考えていなかったためと思われる。ただ、IPアドレスを使うと簡単にノードIDを生成できるので、目的と管理コストを比較した上でどちらかを選ぶのが良いだろう。
- Q)電子証明書の検証手段として、PKIよりもPGPの方が分散環境に適しているように見えるが、PGPを選ばなかった理由は?
- A)PGPの信頼の輪では全ノードに対する検証ができるか怪しいが、PKIであれば管理者が存在するので必ず証明書を検証できる。そのため、PKIを使う方がスマートだと考えている。
グループウェア程度の規模ならPGPでも良いと思うが、数十万の規模になるとPKIの方が良い。
- C)(吉田)私の紹介したPIAXでも、証明書を使っている。ピアはpeerIDを使って認証し、証明書はDHTに格納している。JavaにKeyStoreというクラスがあるのだが、KeyStoreクラスのService Provider Interface(SPI)を定義することで、簡単にDHTのストレージをキーストアとして使うことができる。
しかし、実際作ったのだが、CRL(Certificate Revocation List、証明書失効リスト)とchurn耐性の問題がある。
例えば、あるIDを持ったピアAが一時的に離脱している間に、他のピアによってデータが更新されてしまうと、そのピアAは悪意が無いのに古いデータを公開してしまう。このように、悪意あるノードが無い場合でも、churn耐性の問題は厳しい。レプリケーションをかなりしっかりやらないと、アプリケーション開発者からは「使えない」と言われてしまう(私も言われた)。
もう一点。PIAXではエージェントも認証しているのだが、エージェントの移動にSAMLアサーション(編者注:過去に一度認証されていることを証明する、クッキーのような情報)を利用している。SAMLアサーションは簡単に使えるので、データのストアにも応用できるのではないかと少し考えている。 - A)CRLの問題について。電子証明書だけでなくCRLもDHTに格納しておき、ピアの認証を行うたびに、必ずDHT上の電子証明書およびCRLを検索させればいいのではないかと考えている。
- Q)セキュリティ三大要素のCIAのA(Availability)について。自分が今まで論文を読んできた範囲では、レプリケーションの方法は(1)何も考えずにレプリケートする、(2)エラー訂正コードを使ってRAID的に分散させる、(3)秘密分散法のような仕組みを使う、などがあった。また、Chordの場合はsuccessorsにレプリカを配布するという方法を提案していたが、それら以外の方法を知っていたら教えてほしい。
- A)レプリケーション先を決める方法は難しい。
例えば、Chordの方法では、DDoS攻撃を受けるとノードがsuccessor listの順にダウンしてしまう。その危険性を考えて、講演ではノードID=Hash(X + αY)のノードにレプリカを格納する方法を提案した(資料p.19)。
また、秘密分散法の場合は分散情報を全部集める必要があるので、それが本当にリーズナブルな方法なのかはよく分からない。
- Q)私もノードID=Hash(X + αY)のノードにレプリカを格納する方法を考えたことがあるのだが、レプリケーション先のノードのディスクが溢れる可能性があると思う。その対策は?
- A)レプリケーションノードの数を増やして、ディスクが溢れているノードは諦めるのが一番楽な方法だと思う。
■ 謝辞
この議事録を作成するにあたり、講演者の方々には多大なご協力をいただきました。お忙しい中お時間を割いていただき、本当にありがとうございました。
また、この議事録は講演内容の録音を聞き直しながら作成したのですが、その際にはテープ起こし用の再生ソフトOkoshiyasu2に非常にお世話になりました。Okoshiyasu2作者の「もじょ」氏に感謝いたします。
■ 更新履歴
- 2006/10/02
- 初版を公開しました。
- 2006/10/03
- 読者から指摘のあった記述間違いを修正しました。
- 2006/10/04
- 池嶋氏および西谷氏の講演を追加しました(これで全ての議事録を公開しました)。また、参加者数を「約70名」から「80名弱(講演者含む)」に修正しました。
- 2006/10/11
- プレゼン資料のURL変更に追従しました。
*1 反復(iterative)探索と再帰(recursive)探索の比較については、首藤氏らが執筆した論文「構造化オーバレイにおける反復探索と再帰探索の比較 (SWoPP2006, July 31, 2006)」が詳しい。
*2 Project JXTA Developer Contest(OpenP2P.com)
*3 P2Pwebの定義?(無印吉澤)とか、NECとP2P(無印吉澤)とかを参照。
*4 ちなみに、加藤氏はde Bruijnを"di-buruyan"のような感じで発音していた(強調部分にストレス)。
[ツッコミを入れる]
2006/10/29
■[blog][SNS]Voxはじめました(mixiユーザのための簡単なVox紹介)
Six Apartの新サービス「Vox」が一般公開されたので、試しに使ってみました。これまではmixi同様の招待制でしたが、今後はユーザ登録さえすれば誰でも使えるようです。
簡単に言うと、このVoxというのはmixiからコミュニティ機能と足あと機能を取って、日記の見た目をブログっぽくしたサービスのようです。
ユーザ登録してブログを書いて友達を追加したあとのVoxの使い方は、大まかに言うと「ブログツール」としての使い方と「日記リーダ」としての2通りになります。
■ ブログツールとしての使い方
まず、画面上部にあるコントロール・バーの「マイVoxブログ」をクリックすると、こんな画面が出てきます。
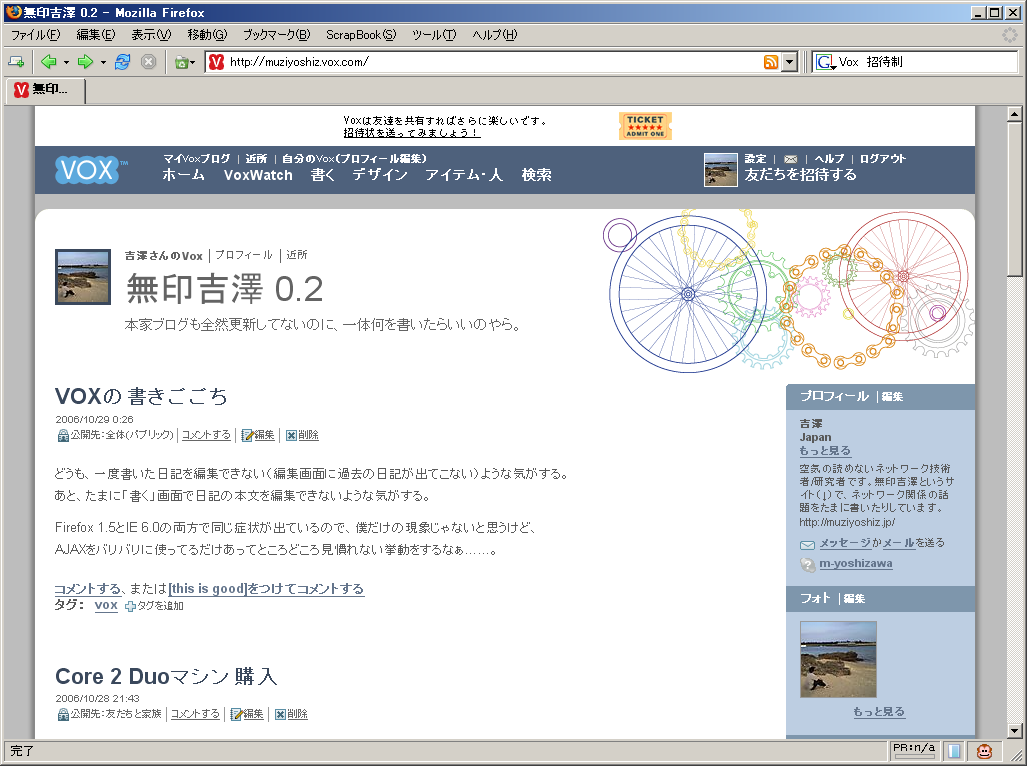
ホントに普通のブログのような見た目ですが、友達関係でのアクセス制限はきちんと出来ているみたいです。ただ、その記事がアクセス制限されてるかどうかが見た目でパッと分からない上に、デフォルト設定は「公開(パブリック)」になってるので、そのあたりが今後mixiみたいに問題になりかねないですけど……。
で、設定を「公開(パブリック)」にしている記事は一般公開されるので、例えば僕のVoxブログの公開記事には http://muziyoshiz.vox.com/ からアクセスできます。
■ 日記リーダとしての使い方
一方、画面上部にあるコントロール・バーの「VoxWatch」をクリックすると、友達(または近所)に登録したユーザの最新日記などを見られるリーダ画面が出てきます。
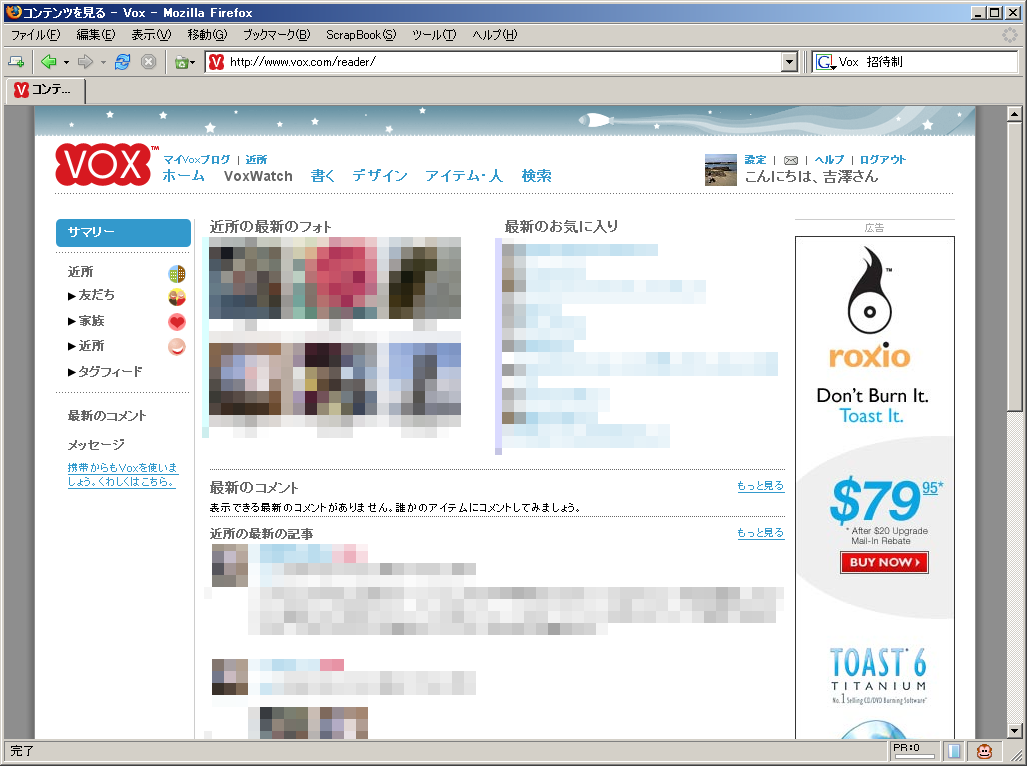
これはちょうど、mixiのトップページでマイミクの最新日記や最新アルバムをチェックするのと同じような機能です。
ただ、Voxでは、mixiの「マイミク」に相当する「友達」関係の他に、mixiの「お気に入り」に似た(一方向の)「近所」関係というのを指定することが出来て、この「近所」関係のユーザの最新日記もこのVoxWatchに出てきます。
要するに、友達を誰も登録しなくても、例えばアルファブロガーな人たちを「近所」指定していけば、単なる日記リーダとしてVoxを使うことも出来るというわけです。まあ、ブログはRSSでも購読できるので、この機能は既に「友達」を登録している人へのオマケ機能と考えた方がいいかもしれませんけど。
■ その他
あと、ユーザ間のやり取りを活性化させるために、運営にも色々工夫してるみたいです。
画面上部から移動できるホーム画面では、毎日「今日の質問(QotD)」「Vox Hunt」という日記のお題を出していて、これに従って日記を書いてもらえれば友達との話題も膨らんでラッキー!みたいな仕組みのようです。僕は面倒なのでやってませんけど。
ともかく、使い心地はあまり悪くないですし、ブログとSNSの間を取ったいいサービスだと思います。mixiからユーザが大勢流れてきたら、しょうもない日記は全部こっちで書くことになるかもなぁ(またネットワーク効果か!)。
参考:
シックス・アパート、SNS要素を備えたブログ「Vox」正式サービス(BroadBand Watch)
http://bb.watch.impress.co.jp/cda/news/15943.html
Vox発進! これは皆さん、気に入るでしょう(TechCrunch Japanese)
http://jp.techcrunch.com/archives/vox-lifts-off-and-youll-love-it/
[ツッコミを入れる]
スパム対策のため、60日以上前の日記へのコメント及びトラックバックは管理者が確認後に表示します。
また、この日記に無関係と判断したコメント及びトラックバックは削除する可能性があります。ご了承ください。
また、この日記に無関係と判断したコメント及びトラックバックは削除する可能性があります。ご了承ください。

