 muziyoshiz.jpまでどうぞ。
muziyoshiz.jpまでどうぞ。
2005/06/07
■[年表][SBM]年表ウェブ(Chronologic Web)の構成要素
※繋がりの多様性を特徴とする「ソーシャル年表サービス」の提案(2005/05/24)の続きです。
前回の日記では「ソーシャル年表サービス」のコンセプトに関する話に終始していましたが、今回からはこのサービスをどうすれば実装できるかを考えてみます。
ちなみに、「ソーシャル年表サービス」という名前は少し長いし語呂が悪いので、今回からは「年表ウェブ(Chronologic Web)」という名前で呼ぶことにしました(Semantic Webと語感を似せたかったので、chronologicalじゃなくてchronologic)。
で、今回はまず以下の要求からスタートして、年表ウェブの構成要素について考察してみます。
■ 要求:良い年表データはいつまでも残したい
前回の日記では、年表ウェブは「扱うデータ(出来事)に日付の情報を組み込んでいるため、時間経過の影響を受けにくい」メリットがあるという話をしましたが、そのメリットを活かすためには、まず年表データ自体が時間経過によって消えない(=いつまでも残せる)必要があります。
つまり、良い年表はその作成者が居なくなったとしても、それを支持する人によって残される。そういう仕組みが年表ウェブには要求されます*1。
そう考えると、年表ウェブを実現するための機能は特定のノードに集中させずに、出来るだけ複数のノードに分散して余裕を持たせるのがよさそうです(特定のノードに集中させると、そのノードがダウンしただけでサービス全体が使えなくなってしまう)。そこで、次はこの年表ウェブを実現するための構成要素について考えてみます。
■ 構成要素
年表ウェブの構成要素は、各機能毎に以下の5つに分けることができます。これらは、いくつかまとめて1つのノードに実装することも、全て別のノードに実装することもできます。
- Repository(保管)
- Certifier(証明)
- Aggregator(集約)
- Viewer(閲覧)
- Creator(作成)
まず、Repositoryは、年表データ(年表、出来事など)を保管し、提供する機能をもつ構成要素です。ユーザがCreatorを通して作成した年表データは、このRepositoryが保管します。また、閲覧するユーザがAggregatorを通して検索条件をRepositoryに渡すと、Repositoryはその条件を満たす年表データを返します(このインタフェイスの詳細は後日まとめます)。
次に、Certifierは、年表データの作成者が誰かを証明するためのデータ(ユーザデータ)を管理する機能を持つ構成要素です。Certifierは年表データを作成するユーザの認証を行います。また、年表データの完全性などもこれが提供します。
Aggregatorは、複数の年表データを集約する機能を持つ構成要素です。年表ウェブから複数の年表、出来事をかき集めて、ユーザの指示に従ってそれらを整形する、RSSリーダ(アグリゲータ)のような役割を果たします。年表ウェブの検索エンジンを作るとしたら、それはアグリゲータの一種になります。
Viewerは、Aggregatorが集約した年表データを閲覧する機能を持つ構成要素です。AggregatorがCGIとして提供される場合は、ViewerはWebブラウザに相当し、Aggregatorがデスクトップ上で動作するソフトウェアとして提供される場合は、Viewerと一体になります。やっぱりRSSリーダに似ていますね。
最後に、Creatorは、年表データを作成し、それをRepositoryに登録する機能を持つ構成要素です。Creatorは、年表データを作成または登録する際に認証情報を扱う必要があります(後述)。
ここまでが、機能の分散を考えるための前準備です。
■ サーバからP2Pネットワークへの移行
で、ここからは、上記の構成要素が、どうやって複数のノードに分散されていくかを、図を見ながら説明していきます。ただ、Creatorは常にユーザに最も近いノードに配置されるため、以下の図では省略しました。
※ちょっと余談になりますけど、実際に年表ウェブを実装するとしたら、最初はC/S(クライアント/サーバ)型の実装でスモールスタートして、徐々にP2P型のネットワークに軸足を移していくのが良いと僕は思っています。その場合も、おおよそ以下の順に移行を進めることになりそうです。
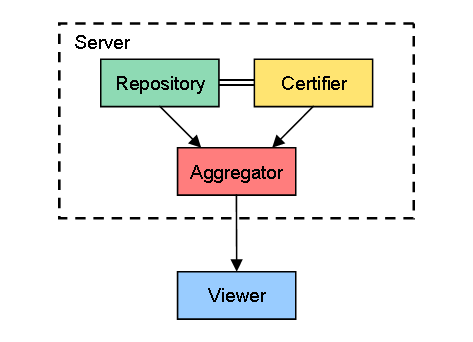
1. データを1つの固定サーバに集中
一番単純なのは、下の図のようにRepository、CertifierそしてAggregatorの機能を1つの固定サーバに集中させるケースです。矢印はデータ(年表データ、ユーザデータ)の流れを表し、二重線は年表データとユーザデータの関連付けを表しています。
現時点で各社から提供されているソーシャルブックマークは、全てこのケースですね。
 (クリックして拡大)
(クリックして拡大)
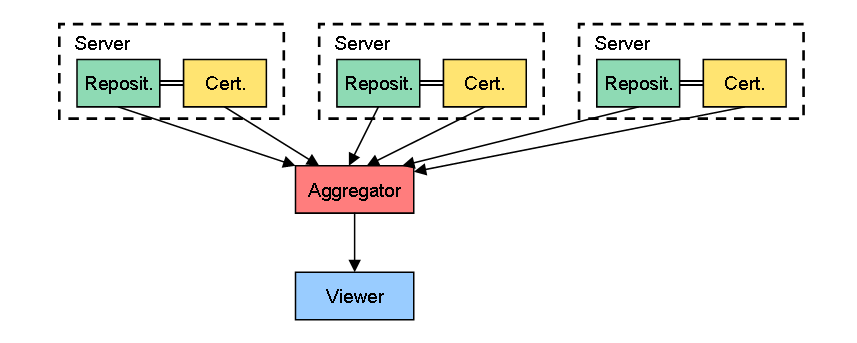
2. データを複数の固定サーバに分散
次に考えられるのが、RepositoryとCertifierのセットを、複数の固定サーバに分散するケースです。これは、現在のWebサーバ、検索エンジン、Webブラウザとちょうど同じような関係になります。
 (クリックして拡大)
(クリックして拡大)
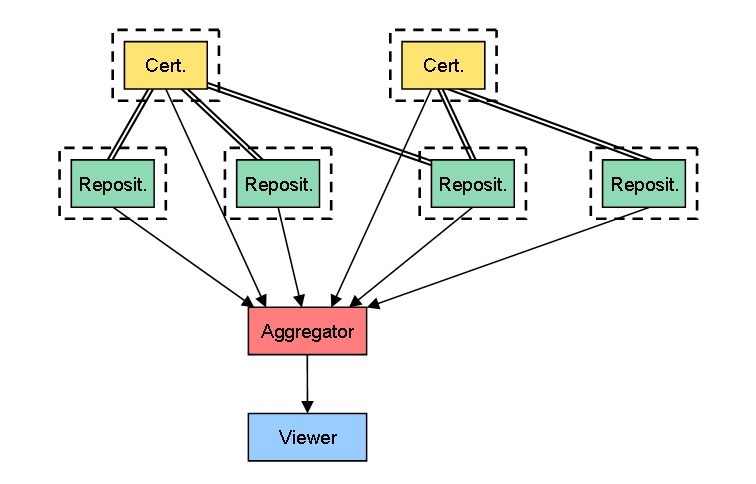
3. RepositoryとCertifierの機能を、異なる固定サーバに分散
これは、RepositoryとCertifierの機能を異なるサーバに分離し、それに加えて1つのCertifierが複数のRepository(正確にはその上の年表データ)をまかなえるようになるケースです。こっちは、TypeKeyのサーバと、無数に存在するMovable Typeの関係に近いですかね。
具体的には、以下のような実装を考えています。
- Creatorは年表データ作成のための公開鍵と秘密鍵を作成し、Certifierからその公開鍵の証明書を発行してもらう(Certifier=CA)
- 証明書はRepository上に保管する
- Creatorは年表データの作成時に、上記の秘密鍵で署名する
- Aggregatorは年表データを集約する際に、その署名が正しいかどうか検証する
 (クリックして拡大)
(クリックして拡大)
4. Repositoryの機能を、動的に構成されるネットワーク上に分散
ここからP2Pネットワークの登場です。これは、Repositoryの機能を、常時起動していることが保証されている固定サーバに持たせるのではなく、出入りのあるノード(ピア)によって動的に形成されるネットワークに持たせるケースです。
P2P掲示板を実現する方法や、DHT(分散ハッシュテーブル)を使えば実現できそうな気がします。P2P勉強会で講演したことあるような人に聞いてみたら、具体的にどうすればいいか分かるかも……。
このケースでは、まだCertifierの機能を固定サーバに頼っています。その意味では、ログイン時(認証あり)のみ固定サーバにアクセスし、それ以降はスーパーノードに接続する、という動作を行う現在のSkypeに似た構成とも言えます。
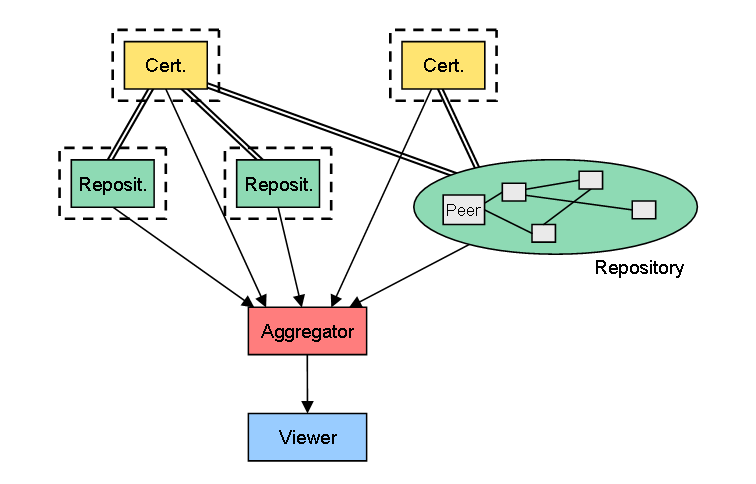 (クリックして拡大)
(クリックして拡大)
5. Certifierの機能を、動的に構成されるネットワーク上に分散
そして最後は、Certifierの機能までも、固定サーバからP2Pネットワークへと移行させたケースです。ここでは、PGPに代表されるような、証明書配布のための評判システムが重要になります。
ここまでする必要があるかどうかはともかくとして、ちょっと面白そうですね。
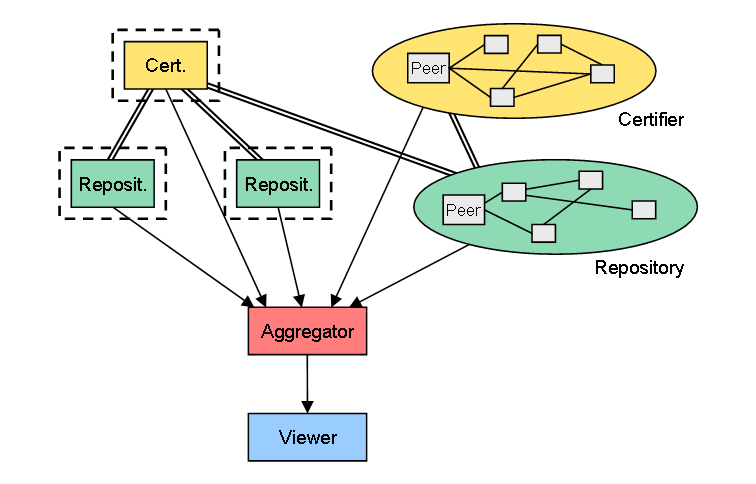 (クリックして拡大)
(クリックして拡大)
■ まとめ
年表は、長い年月を経た後にこそ価値があります。それは、例えば最近発売された教科書には載らないニッポンのインターネットの歴史教科書を見るとよく分かります(僕も買いました&だいぶ影響されてます)。
そこで、年表を後々まで残すためには、年表ウェブを実現するための機能を特定のノードに集中させず、出来るだけ複数のノードに分散できることが重要になります。今回は、1つの固定ノードから複数の固定ノードへの分散、更に固定ノードから出入りのあるノード(ピア)への分散まで考えてみました。
次回はより具体的な実装の話――例えば、Repositoryのインタフェイス、Repositoryと分離したIDの決定方法、正しい利用と不正利用の切り分け、匿名性の扱い、等――の中から何かテーマを選んで書いてみます。
ところで。
現在、国内のソーシャルブックマークは「はてなブックマーク」が主流になりつつありますけど、今回の検討内容と同じような形でソーシャルブックマークも分散化できると思います。……誰かやってみませんか?
*1 これはライセンスの問題と密接に絡むのですが、そのあたりはまだちゃんと検討しきれてないので省略します。うーん……。
[ツッコミを入れる]
本日のTrackBacks(全1件)
[]
年表ウェブのさらに細かい話です。
スパム対策のため、60日以上前の日記へのコメント及びトラックバックは管理者が確認後に表示します。
また、この日記に無関係と判断したコメント及びトラックバックは削除する可能性があります。ご了承ください。
また、この日記に無関係と判断したコメント及びトラックバックは削除する可能性があります。ご了承ください。

